Designing Rasa training stories (from rasa blog)

Training data is an essential part of every machine learning model. It is no different when it comes to conversational AI. We designed Rasa Core so that instead of writing rules, your assistant could observe what real conversations look like, learn from them and use that knowledge to manage the dialogue.
Modelling dialogue is not an easy task due to the natural complexity of human language. This calls for the mindful design of conversational data to optimize what patterns your assistant learns. In Rasa terms, this conversational data is called Rasa stories.
But how do you actually design them? In this post, we are going to cover the best practices of designing Rasa training stories and what you should keep in mind to build your best conversational AI. The examples in this post include stories from Sara, the open source onboarding assistant in the Rasa docs, built with the Rasa Stack. You can find the open source code of Sara here.
Outline
- Introduction to Rasa stories
- How to get started with creating training stories?
- Designing stories with Slots
- Stories with Rasa Forms
- Handling Chitchat
- So… how many training stories do I need?
- Summary
- Resource
Introduction to Rasa stories
Rasa stories are a form of training data used to train the Rasa Core dialogue management models. A story is a representation of an actual conversation between a user and an AI assistant, converted into a specific format where user inputs are expressed as corresponding intents (and entities where necessary) while the responses of an assistant are expressed as corresponding action names.
Below is an example of what building blocks the Rasa story consists of:
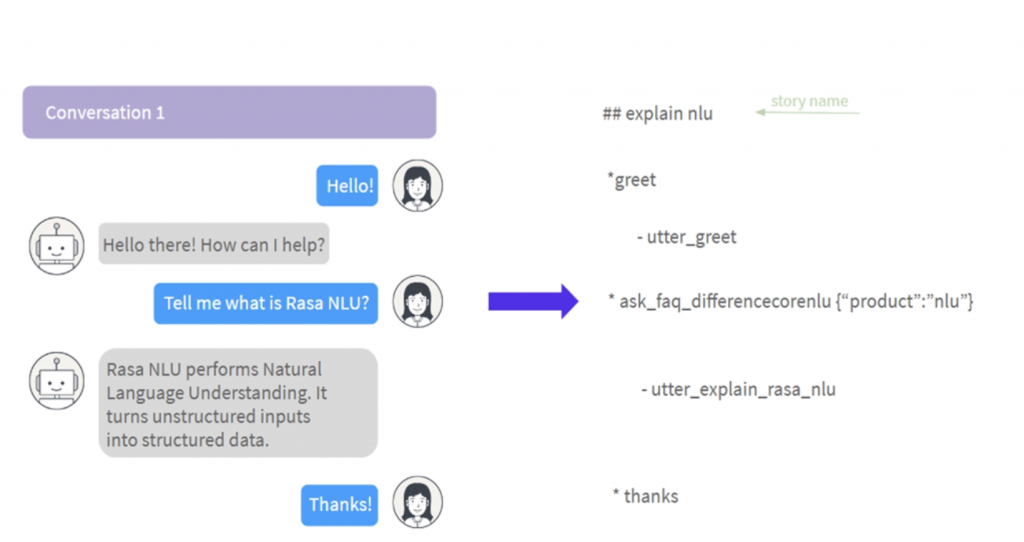
- A story starts with a name which has a prefix ‘##’. It is not mandatory but greatly advised to assign names to stories, as they make it much easier to read and debug them. When naming your stories, it’s best to give purposeful and unique names which clearly indicates what kind of conversation the story represents.
- User inputs are represented by corresponding intents and start with ‘*’.
- If at a specific state of the conversation, important entities are extracted and have an influence on the direction of the conversation, they have to be included in a story too by specifying the name and the value of the entity inside the curly brackets next to an intent.
- The responses of the assistant are represented by action names and are included in the training stories with a prefix ‘-’.
- All stories should end with an empty line which marks the end of a training story.
Note, that in your stories, one user intent can be followed by more than one utterance. For example, the story below shows that once the user asks what is Rasa NLU, the AI assistant first responds with a message confirming that it can handle the request and after that, provides an actual response to the question that has been asked:

By observing the training stories, dialogue management model learns how the current user input and the previous states of the conversations influence the prediction of the next response. But how do you get this conversational training data in the first place? We cover this in the next section of this post.
How to get started with creating training stories?
Getting training data is a common challenge we see new Rasa developers dealing with. It’s challenging because there aren’t many publicly available conversational data sources out there. Additionally, most of the time the training data for your AI assistant has to be custom-tailored for your specific domain and use case. So, it’s very likely that you have to start with generating training data from scratch.
Generating training data
To make this process easier and more efficient, you should start with designing the flow of the happy path first to understand what the most common conversations between the user and your assistant will look like. For this, you can use tools like Botsociety which enable you to design conversations, check how they are going to look like on your preferred messaging platform, and most importantly — export them in a Rasa format and move to the development stage right away. After designing the happy path, you should generate more examples of simple stories which would cover some deviations from the happy path. There are three Rasa Core features which you can leverage to generate more training stories easier — interactive learning, checkpoints and OR statements.
Interactive learning
Interactive learning is a great way to train your AI assistant and generate training stories while speaking to your bot. During the interactive learning session, the bot asks you to provide feedback for every prediction it made — intent classification as well as response prediction. All conversations you have with your AI assistant in an interactive learning session can later be exported as NLU and dialogue training examples and attached to your original training data sample. Using interactive learning you can also visualize the training stories and see how the conversation flow changes as you speak to your assistant.
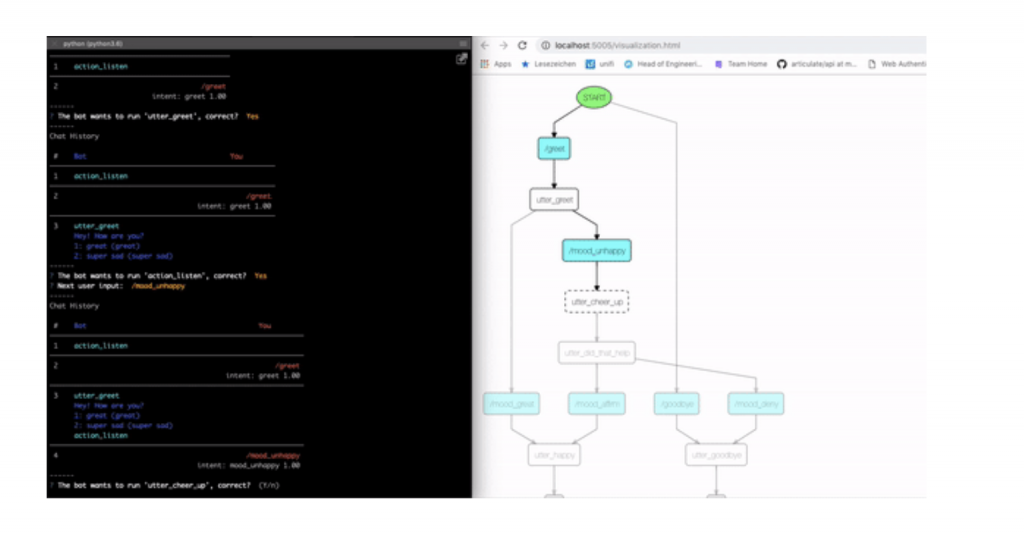
To train your assistant in an interactive learning session, you need to have at least a few training stories beforehand. This is where you can get the most from the previously mentioned Rasa and Botsociety integration — design the happy path with Botsociety, export it in a Rasa format and use the exported stories to train your assistant in an interactive learning session.
Checkpoints
Checkpoints can help you modularize the stories. The main idea of the checkpoint is that you can create a blueprint of the story which can later be appended to any story using a checkpoint name rather than writing the entire story by hand. To create a checkpoint, you have to add a > checkpoint_nameat the end of the conversation part which you want to reuse. For example:

This means that now you can add this conversation part to any other story in your training data file by referencing the name of the checkpoint. Below are two example stories to illustrate this. Both stories begin with a previously checkpointed ## first story and then continues with either user’s input affirm or deny:

While checkpoints can save you some time generating training stories, they can very quickly lead to serious memory issues and make your training stories very difficult to read. That’s why you should be very mindful with where and when you use checkpoints and rely on them only if absolutely necessary.
OR statements
Another way to write more stories faster is by using OR statements for possible intents at a specific state of the conversation. In this way, you can cover more different dialogue turns with the same story. For example, a story below covers two different dialogue turns providing two possible intents a user might use at that specific state of the dialogue:

The best part is that there is no specific number of how many intents you can include in a OR statement. However, just like with checkpoints, an overuse of OR statements might lead to memory issues when training your assistant and it can also be an indicator that some of the intents in your NLU training data should be merged.
As soon as you have the basics of your assistant working, you should let the real users help you improve your assistant. To do that, give your assistant to the real users to chat, collect the conversational data and observe how the conversations between them and your AI assistant look like. It allows you to better understand what conversations your chatbot should be able to handle, what new skills your AI assistant should learn and most importantly — you have a great training data source to constantly improve your bot.
Now when you know how to generate training data, let’s take a look at some of the most common cases and best practices of designing the training stories.
Designing Stories with Slots
In addition to classified intents, extracted entities and previous dialogue states, the predictions of the dialogue management model can be influenced by slots. Slots are key-value stores designed to keep the context of the conversation by storing important pieces of information throughout the conversation or until reset. Using slots, you can model when the assistant should ask for the necessary details and when to skip these questions if the details were already provided.
For example, one of Sara’s skills is to subscribe a new Rasa user to the Rasa newsletter. To do that, the assistant has to know the user’s email because, without it, the assistant is not able to execute the action. So the goal is to teach the assistant that if the user hasn’t provided their email, the assistant should ask for it, but if they did, then the assistant should skip the question and move on to the next state of the conversation. Such behaviour can be modelled using slots — if the email slot is not populated, the assistant will ask for this information, but if the slot is already filled, then the assistant should be good to execute the action. A method slot{} in Rasa stories specifies that a specific slot is set at the specific state of the conversation. Below are two example stories demonstrating how slot{} events at the different stages of the conversation influence the dialogue. A story where the user does not provide the email with the initial request:

and a story where the user provides the email with the initial request:
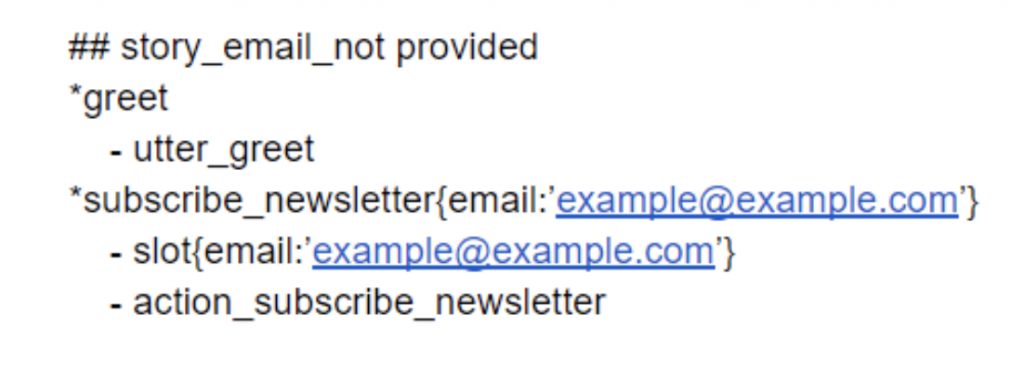
If you have a slot called email and your NLU model extracts an entity called email, then the slot is set automatically once the entity is extracted. Therefore in such situations, you don’t need to include slot{} method in your stories. If you use interactive learning to generate stories, slot{} methods are added automatically to your stories so you don’t have to worry about them at all.
Slots are the key when modelling different dialogue turns depending on extracted details. There are different slots types that you can use to determine how they should influence the predictions of the next actions. You can specify slot types when defining the domain of your assistant. For example, with slot type text only the presence or absence of the slot influences what an AI assistant does next (just like in the example above). But in other cases, you might want to use categorical or boolean slots which would take into account the actual value of the slot, or you might want to use unfeaturized slots to simply store the information without influencing the predictions. You can read more about different slot types available in Rasa Core here.
In some situations, details returned by custom actions can also influence the dialogue. Slots returned by custom actions provide information about the outside world and drive the conversation to a specific direction. For example, in the newsletter subscription example used above, the behaviour of the assistant differs depending on whether the user is already a subscriber of the newsletter or not. In this case, a custom action can check if the user has already subscribed to the newsletter and set a boolean slot to True or False using a SlotSet() method:

This behaviour has to be reflected in the training stories as well. To do that, you should include the slot{} event to your stories after the custom action which sets the slot (if you use interactive learning, this will be done for you automatically). Below is an example of how the value of the slot filled by a custom action can influence the flow of the conversation. If the user is not yet a subscriber, the assistant makes a subscription and sends a confirmation email to the user, but if the user is already a subscriber, an assistant sends a message that the user already has a subscription:

You should use slots if your AI assistant needs to collect only one or two pieces of information to execute a specific action, but often, your assistant needs to collect many more details than that. In cases when the assistant needs to fill in more than just a couple of slots, designing training stories with only slots gets complicated as the complexity of the stories grows with every additional piece of information that is required. In addition to that, you will likely need a lot of training stories to even cover a happy path, let alone the deviations from it. To go around this issue and avoid the stories getting very long, you should use Rasa Forms for slot filling which we cover in the next step of this post.
Stories with Rasa Forms
Rasa Forms are an important Rasa feature which allows you to design the happy path of your AI assistant much easier and make slot filling more reliable. For example, using Sara, Rasa users can book a sales call to learn more about Rasa enterprise features. Before scheduling a call, Sara has to know quite a few important details about the user: user’s job position, the use case, name, company, etc. To model such conversations with only slots, you would have to think of at least a few different ways of how the user can provide these details (provide them all with the initial request, provide some of them with the original request, only provide them when explicitly asked, etc). Instead, using Rasa Forms such situations can be modelled with one single story and ensure that the chatbot has all the details collected before moving forward. Below is an example story with a Rasa Form:

The main idea behind the Rasa Forms is that once a form is activated, FormPolicy takes over the dialogue management and uses form actions to check which required slots are still missing. Once all slots are set, the form is deactivated and FormPolicy hands over the dialogue management to other policies specified in your configuration file. You can find more details on how to configure forms actions here.
Obviously, the users will not always follow the happy path — often they might refuse to provide a required piece of information or say something unrelated to the assistant’s goal. To model such situations, your stories should include intermediate actions within the form action session. For example, the story below represents a situation where the user decided to stop providing the information in the middle of the form action session but later came back to provide the required details:

Since stories with Rasa Forms can get complicated, especially when modelling the deviations from the happy path, we recommend using interactive learning for generating training data.
When developing your contextual AI assistant, it’s very likely that you have to deal with even more severe deviation from the happy path. For example, it’s very likely that at some point your users completely drift from their initial goal and start the so-called chitchat — saying things which are completely unrelated to assistant’s domain. In the next step of this post, we look into the best ways to handle that.
Handling chitchat
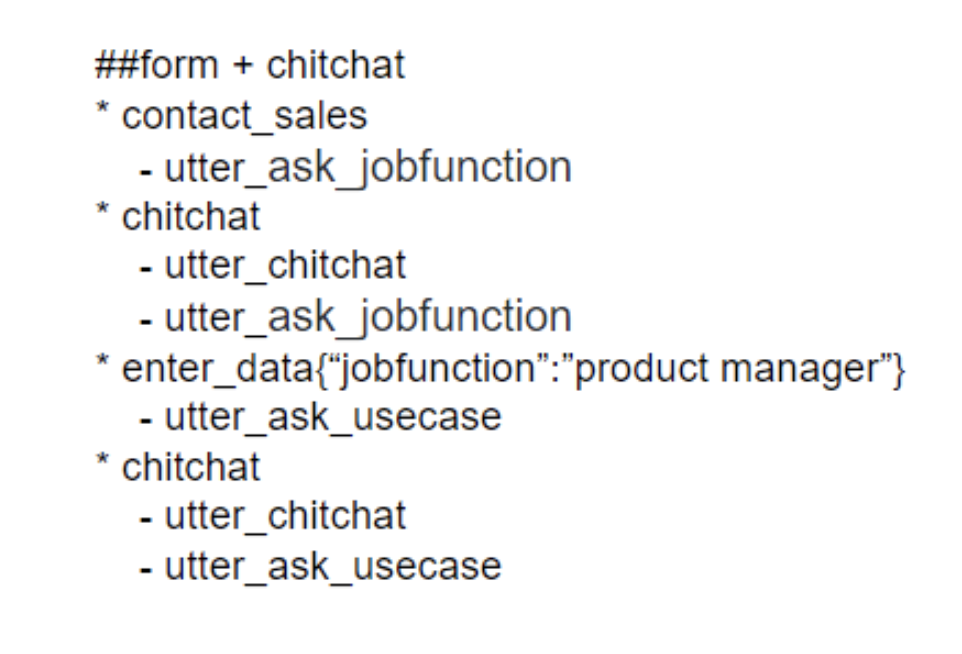
Chitchat is a form of so-called uncooperative behaviour where the users talk about the things which are completely unrelated to what the bot is intended to do. An example of such behaviour could be the user asking a restaurant search assistant what movies it could recommend watching, or who is the president of the United States. While it’s very difficult to enable your AI assistant to have a different and natural response to each case of chitchat, it’s important to at least identify and handle it as gracefully as possible. So how do you identify chitchat? The best approach is to create a separate intent called, for example, chitchat and train it on various inputs, unrelated to what the assistant actually does. Then, once your NLU model is capable of distinguishing chitchat from other intents, you can include them in your stories where the chitchat actually occurs.
How your assistant responds to chitchat depends on you. A simple approach could be just to respond with a universal utterance like ‘Sorry, I can’t help you with that’. An example story for such a situation looks as follows:

Since the chitchat can occur at any state of the conversation, you would naturally need quite a lot of training examples to handle it properly with regular training policies. To solve this issue, we are working on a new policy, called MappingPolicy, which makes it much easier to handle chit-chat and FAQ-like interactions. The main idea of MappingPolicy is that it allows you to specify if some intents should be mapped to specific actions which would then ensure that once specific intents are recognised (for example chitchat) the AI assistant always responds with a mapped action (for example utter_chitchat) and ignores everything that happened in a conversation before. To specify which intents should be mapped to which actions, in your domain file you should add “triggers” method to the specific intents. An example below means that once the NLU model identifies chitchat input, it triggers the utter_chitchat response:

MappingPolicy is still a work in progress, but it should be merged to the Rasa Core master branch in the next few days.
Identifying and responding to chitchat is just one part of the job in goal-oriented assistants. What’s also extremely important is to enable your assistant to take charge of the conversation and bring the user back to the initial path of the conversation. To achieve that, your stories should include not only the utterances which respond to chitchat but also the responses which would remind the user of what the conversation was before the chitchat occurred. The story below is a good example of that — once the user starts chitchat, an assistant responds to it and reminds the latest request it sent to the user before the chitchat happened:
To model such conversation you can try out the Rasa EmbeddingPolicy which was specifically designed to deal with uncooperative user behaviour and therefore generalises better on unseen conversations.
So… how many training stories do I need?
This is a very common and important question. While there is no rule of thumb for how many stories you should have to build an assistant that works, a couple dozen of training stories should be enough to kickstart the development. With more training stories your AI assistant learns to generalise better and handle more complicated deviations from the happy path. It’s important to keep in mind that in order to achieve that, the stories in your training data file have to be dynamic and cover different dialogue turns. To build a production-ready assistant you will likely need at least a few hundred training stories (depending on the domain and the complexity of the conversations you want your assistant to handle). As the amount of training data grows, you may consider splitting training data into different files for easier debugging. If you do, then you can pass the folder with the training data files to the Rasa Core train function and all the files inside the folder will be treated as they were part of one big training data file. Below is an example of how the folder structure would look like with multiple training data files:

Training data plays a crucial part in building a successful AI assistant. How much and what kind of stories you need always depends on your use case so it’s important to keep in mind what users you are developing your assistant for. We are constantly looking for ways to make the creation of conversational data easier and more effective. We would love to hear about your experience in generating training stories for the Rasa Core models. Share it with us by joining the discussion on this thread of the Rasa Community Forum


