Survey on Distributed Representations

Introduction
Distributional semantics is a subfield of natural language processing predicated on the idea that word meaning is derived from its usage. The distributional hypothesis states that words used in similar contexts have similar meanings. That is, if two words often occur with the same set of words, then they are semantically similar in meaning. A broader notion is the statistical semantic hypothesis, which states that meaning can be derived from statistical patterns of word usage. Distributional semantics serve as the fundamental basis for many recent computational linguistic advances. In this survey, we introduce the notion of word embeddings that serve as core representations of text in deep learning approaches. We start with the distributional hypothesis and explain how it can be leveraged to form semantic representations of words. We discuss the common distributional semantic models including word2vec and GloVe and their variants. We address the shortcomings of embedding models and their extension to document and concept representation. Finally, we discuss several applications to natural language processing tasks
Related Works
Vector Space Model
Vector space models (VSMs) represent a collection of documents as points in a hyperspace, or equivalently, as vectors in a vector space. They are based on the key property that the proximity of points in the hyperspace is a measure of the semantic similarity of the documents. In other words, documents with similar vector representations imply that they are semantically similar. VSMs have found widespread adoption in information retrieval applications, where a search query is achieved by returning a set of nearby documents sorted by distance
Curse of Dimensionality
VSMs can suffer from a major drawback if they are based on high-dimensional sparse representations. Here, sparse means that a vector has many dimensions with zero values. This is termed the curse of dimensionality. As such, these VSMs require large memory resources and are computationally expensive to implement and use. For instance, a term-frequency based VSM would theoretically require as many dimensions as the number of words in the dictionary of the entire corpus of documents. In practice, it is common to set an upper bound on the number of words and hence, dimensionality of the VSM. Words that are not within the VSM are termed out-of-vocabulary (OOV). This is a meaningful gap with most VSMs in that they are unable to attribute semantic meaning to new words that they haven’t seen before and are OOV.
Word Representations
One of the earliest use of word representations dates back to 1986. Word vectors explicitly encode linguistic regularities and patterns. Distributional semantic models can be divided into two classes, co-occurrence based and predictive models. Co occurrence based models must be trained over the entire corpus and capture global dependencies and context, while predictive models capture local dependencies within a (small) context window. The most well-known of these models, word2vec and GloVe, are known as word models since they model word dependencies across a corpus. Both learn high-quality, dense word representations from large amounts of unstructured text data. These word vectors are able to encode linguistic regularities and semantic patterns, which lead to some interesting algebraic properties.
Co-occurrence
The distributional hypothesis tells us that co-occurrence of words can reveal much about their semantic proximity and meaning. Computational linguistics leverages this fact and uses the frequency of two words occurring alongside each other within a corpus to identify word relationships. Pointwise Mutual Information (PMI) is a commonly used information-theoretic measure of co-occurrence between two words w1 and w2:
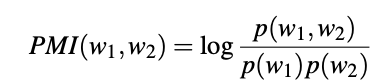
where p(w) is the probability of the word occurring, and p(w1,w2) is joint probability of the two words co-occurring. High values of PMI indicate collocation and coincidence (and therefore strong association) between the words. It is common to estimate the single and joint probabilities based on word frequency and co-occurrence within the corpus. PMI is a useful measure for word clustering and many other tasks.
LSA
Latent semantic analysis (LSA) is a technique that effectively leverages word cooccurrence to identify topics within a set of documents. Specifically, LSA analyzes
word associations within a set of documents by forming a document-term matrix
(see Fig. 5.2), where each cell can be the frequency of occurrence or TFIDF of
a term within a document. As this matrix can be very large (with as many rows
as words in the vocabulary of the corpus), a dimensionality reduction technique
such as singular-value decomposition is applied to find a low-rank approximation.
This low-rank space can be used to identify key terms and cluster documents or for
information retrieval
Neural Language Models
Recall that language models seek to learn the joint probability function of sequences of words. As stated above, this is difficult due to the curse of dimensionality—the sheer size of the vocabulary used in the English language implies that there could be an impossibly huge number of sequences over which we seek to learn. A language model estimates the conditional probability of the next word wT given all previous words wt:
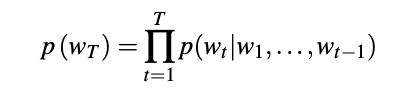
Many methods exist for estimating continuous representations of words, including latent semantic analysis (LSA) and latent Dirichlet allocation (LDA). The former fails to preserve linear linguistic regularities while the latter requires huge computational expense for anything beyond small datasets. In recent years, different neural network approaches have been proposed to overcome these issues. The representations learned by these neural network models are termed neural embeddings. In 2003 [Bengio 2003] presented a neural probabilistic model for learning a distributed representation of words. Instead of sparse, high-dimensional representations, the Bengio model proposed representing words and documents in lower-dimensional continuous vector spaces by using a multilayer neural network to predict the next word given the previous ones. This network is iteratively trained to maximize the conditional log-likelihood J over the training corpus using back-propagation:
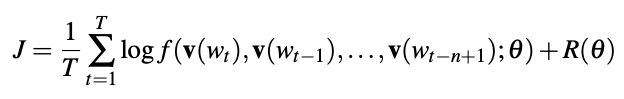
where v(wt) is the feature vector for word wt, f is the mapping function representing
the neural network, and R(θ) is the regularization penalty applied to weights θ
of the network. In doing so, the model concurrently associates each word with a
distributed word feature vector as well as learning the joint probability function of
word sequences in terms of the feature vectors of the words in the sequence. For
instance, with a corpus of vocabulary size of 100,000, a one-hot encoded 100,000-
dimensional vector representation, the Bengio model can learn a much smaller 300-
dimensional continuous vector space representation.[Collobert 2008] applied word vectors to several NLP tasks and showed that word vectors could be trained in an unsupervised manner on a corpus and used to significantly enhance NLP tasks. They used a multilayer neural network trained in an end-to-end fashion. In the process, the first layer in the network learned distributed word representations that are shared across tasks. The output of this word representation layer was passed to downstream architectures that were able to output part-of-speech tags, chunks, named entities, semantic roles, and sentence likelihood. The model is an example of multitask learning enabled through the adoption of dense layer representations.
word2vec
In 2013, [Mikolov 2013] proposed a set of neural architectures could compute continuous representations of words over large datasets. Unlike other neural network architectures for learning word vectors, these architectures were highly computationally efficient, able to handle even billion-word vocabularies, since they do not involve dense matrix multiplications. Furthermore, the high-quality representations learned by these models possessed useful translational properties that provided semantic and syntactic meaning. The proposed architectures consisted of the continuous bag-of-words (CBOW) model and the skip-gram model. They termed the group of models word2vec. They also proposed two methods to train the models based on a hierarchical softmax approach or a negative-sampling approach. The translational properties of the vectors learned through word2vec models can provide highly useful linguistic and relational similarities. In particular, Mikolov et al revealed that vector arithmetic can yield high-quality word similarities and analogies. They showed that the vector representation of the word queen can be recovered from representations of king, man, and woman by searching for the nearest vector based on cosine distance to the vector sum:
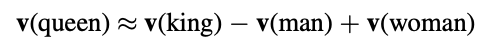
The global co-occurrence based models can be the alternative to predictive, local context window methods like word2vec. Co-occurrence methods are usually very
high dimensional and require much storage. When dimensionality reduction methods are used like in LSA, the resulting representations typically perform poorly in capturing semantic word regularities. Furthermore, frequent co-occurrence terms tend to dominate. Predictive methods like word2vec are local-context based and generally perform poorly in capturing the statistics of the corpus. [Pennington 2014] proposed a log-bilinear model that combines both global co-occurrence and shallow window methods. They termed this the GloVe model, which is play on the words Global and Vector. The GloVe model is trained via least squares using the cost function:
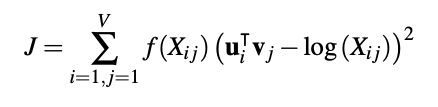
where V is the size of the vocabulary, Xi j is the count of times that words i and j cooccur in the corpus, f is a weighting function that acts to reduce the impact of frequent counts, and ui and vj are word vectors. It is well known that the distributional hypothesis holds for most human languages. This implies that we can train word embedding models in many languages [Coulmance 2016], and companies such as Facebook and Google have released pre-trained word2vec and GloVe vectors for up to 157 languages [Grave 2018]. These embedding models are monolingual—they are learned on a single language. Several languages exist with multiple written forms. For instance, Japanese possesses three distinct writing systems (Hiragana, Katakana, Kanji). Mono-lingual embedding models cannot associate the meaning of a word across different written forms. The term word alignment is used to describe the NLP process by which words are related together across two written forms across languages
Limitations of Word Embeddings
Embedding models suffer from a number of well-known limitations. These include out-of-vocabulary words, antonymy, polysemy, and bias. We explore these in detail in the next sections.
Out of Vocabulary
The Zipfian distributional nature of the English language is such that there exists a huge number of infrequent words. Learning representations for these rare words would require huge amounts of (possibly unavailable) data, as well as potentially excessive training time or memory resources. Due to practical considerations, a word embedding model will contain only a limited set of the words in the English language. Even a large vocabulary will still have many out-of-vocabulary (OOV) words. Unfortunately, many important domain-specific terms tend to occur infrequently and can contribute to the number of OOV words. This is especially true with domain-shifts. As a result, OOV words can have crucial role in the performance NLP tasks. With models such as word2vec, the common approach is to use a “UNK” representation for words deemed too infrequent to include in the vocabulary. This maps many rare words to an identical vector (zero or random vectors) in the belief that their rarity implies they do not contribute significantly to semantic meaning. Thus, OOV words all provide an identical context during training. Similarly, OOV words at test time are mapped to this representation. This assumption can break down for many reasons, and a number of methods have been proposed to address this shortfall. Ideally, we would like to be able to somehow predict a vector representation that is semantically similar to either words that are outside our training corpus or that occurred too infrequently in our corpus. Character-based or subword (char-n-gram) embedding models are compositional approaches that attempt to derive a meeting from parts of a word (e.g., roots, suffixes) Subword approaches are especially useful for foreign languages that are rich in morphology such as Arabic or Icelandic
Antonymy
Another significant limitation is an offshoot of the fundamental principle of distributional similarity from which word models are derived—that words used in similar contexts are similar in meaning. Unfortunately, two words that are antonyms of each other often co-occur with the same sets of word contexts:
I really hate spaghetti on Wednesdays.
I really love spaghetti on Wednesdays.
While word embedding models can capture synonyms and semantic relationships, they fail notably to distinguish antonyms and overall polarity of words. In other words, without intervention, word embedding models cannot differentiate between synonyms and antonyms and it is common to find antonyms closely colocated within a vector space model.
An adaptation to word2vec can be made to learn word embeddings that disambiguate polarity by incorporating thesauri information [Ono 2015]
Polysemy
In the English language, words can sometimes have several meanings. This is known as polysemy. Sometimes these meanings can be very different or complete opposites of each other. Look up the meaning of the word bad and you might find up to 46 distinct meanings. As models such as word2vec or GloVe associate each word with a single vector representation, they are unable to deal with homonyms and polysemy. Word sense disambiguation is possible but requires more complex models. Humans do remarkably well in distinguishing the meaning of a word based on context. In the sentences above, it is relatively easy for us to distinguish the different meanings of the word play based on the part-of-speech or surrounding word context. This gives rise to multi-representation embedding models that can leverage surrounding context (cluster-weighted context embeddings) or part-of-speech (sense2vec). Sense2vec is a simple method to achieve world-sense disambiguation that leverages supervised labeling such as part-of-speech [Trask 2015]
on-going research
Methods such as word2vec or GloVe ignore the internal structure of words and associate each word (or word sense) to a separate vector representation. For morphologically rich languages, there may be a significant number of rare word forms such that either a very large vocabulary must be maintained or a significant number of words are treated as out-of-vocabulary (OOV). As previously stated, out-ofvocabulary words can significantly impact performance due to the loss of context from rare words. An approach that can help deal with this limitation is the use of subword embeddings [Bojanowski 2016] where vector representations are associated with character n-grams g and words wi are represented by the sum of the n-gram vectors. While word embedding models capture semantic relationships between words, they lose this ability at the sentence level. Sentence representations are usually expressed the sum of the word vectors of the sentence. This bag-of-words approach has a major flaw in that different sentences can have identical representations as long as the same words are used. To incorporate word order information, people have attempted to use bag-of-n-grams approaches that can capture short order contexts. However, at the sentence level, they are limited by data sparsity and suffer from poor generalization due to high dimensionality [Le 2014] proposed an unsupervised algorithm to learn useful representations of sentences that capture word order information. Their approach was inspired by Word2Vec for learning word vectors and is commonly known as doc2vec. It generates fixed-length feature representations from variablelength pieces of text, making it useful for application to sentences, paragraphs, sections, or entire documents. In the past year, a number of new methods leveraging contextualized embeddings have been proposed. These are based on the notion that embeddings for words should be based on contexts in which they are used. This context can be the position and presence of surrounding words in the sentence, paragraph, or document. By generatively pre-training contextualized embeddings and language models on massive amounts of data, it became possible to discriminatively fine-tune models on a variety of tasks and achieve state-of-the-art results. This has been commonly referred to as “NLP’s ImageNet moment”. One of the notable methods is the Transformer model, an attention-based stacked encoder–decoder architecture that is pre-trained at scale [Vaswani 2017]. Another important method is ELMo, short for Embeddings from Language Models, which generates a set of contextualized word representations that effectively capture syntax and semantics as well as polysemy. These representations are actually the internal states of a bidirectional, character-based LSTM language model that is pre-trained on a large external corpus.
Building on the power of Transformers, a method has recently been proposed called BERT, short for Bidirectional Encoder Representations from Transformers. BERT is a transformer-based, masked language model that is bidirectionally trained to generate deep contextualized word embeddings that capture left-to-right and right-to-left contexts. These embeddings require very little fine-tuning to excel at downstream complex tasks such as entailment or question-answering BERT has broken multiple performance records and represents one of the bright breakthroughs in language representations today [Devlin 2018].
Conclusion
Word embeddings have been found to be very useful for many NLP tasks. In this survey we have presented an extensive overview of semantically-grounded models for constructing distributed representations of meaning. Word embeddings have been shown to provide interesting semantic properties that can be applied to most language applications.
Reference
Yoshua Bengio et al. “A neural probabilistic language model”. In: JMLR (2003), pp. 1137–1155.
Ronan Collobert and Jason Weston. “A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning”. In: Proceedings of the 25th International Conference on Machine Learning. ACM, 2008, pp. 160–167
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. “GloVe: Global Vectors for Word Representation”. In: Empirical Methods in Natural Language Processing (EMNLP). 2014, pp.1532–1543.
Jocelyn Coulmance et al. “Trans-gram, Fast Cross-lingual Word embeddings”. In: CoRR abs/1601.02502 (2016).
Edouard Grave et al. “Learning Word Vectors for 157 Languages”. In: CoRR abs/1802.06893 (2018).
Masataka Ono, Makoto Miwa, and Yutaka Sasaki. “Word Embedding based Antonym Detection using Thesauri and Distributional Information.” In: HLT-NAACL. 2015, pp.984–989.
Andrew Trask, Phil Michalak, and John Liu. “sense2vec – A Fast and Accurate Method for Word Sense Disambiguation In Neural Word Embeddings.” In: CoRR abs/1511.06388 (2015).
Piotr Bojanowski et al. “Enriching Word Vectors with Subword Information”. In: CoRR abs/1607.04606 (2016).
Quoc V. Le and Tomas Mikolov. “Distributed Representations of Sentences and Documents”. In: CoRR abs/1405.4053 (2014).
Ashish Vaswani et al. “Attention is all you need”. In: Advances in Neural Information Processing Systems. 2017, pp. 5998–6008.
Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.” In: CoRR abs/1810.04805 (2018)


