Neural Turing Machines
In this blog, we will target on one of the two main foundations of Rasa Core called Neural Turing Machine; we will also read together the original paper which can be found at the following link https://arxiv.org/pdf/1410.5401.pdf. Reading paper is tough; indeed!!! when you are not get familiar with it; i believe that you will loose focus quickly and give up because it was me over 10 years ago ^^ .. so let’s dive right in
Abstract

This section give you a very high level of what the paper is about. When you are a experience researcher; you should decide to keep reading or not basing on the content of the abstract of the paper. so the most important information about this abstract is:
We extend the capabilities of neural networks by coupling them to external memory resources, which they can interact with by attentional processes
so what they are trying to do here is create an external memory and hook it up to the neural networks to extend their capabilities. And how the external memory and neural networks are connected? — > attention
and that all you need to remember for the abstract
Introduction
The next section is introduction; as the name of section states its purpose is to serve you with the introductory information about research; this is just like the brief overview about the whole research paper. believe me or not; many researchers write the introduction at very last of their research process


some important information that you should take away from this section:
- How computer works
- RNNs have ability to carry out the information over very long period of time
- NTM is a differentiable computer that can be trained by gradient descent
- How NTM links to human cognition
- The organization of the paper
Foundational Research
This section is also call related works alternatively. Academically, this section explains how some other research works might be related with this research work. In this section; researchers usually point out the resemble previous works with their strengths and limitations. This help to prove the motivation for the author’s research


As shown in the title this sub-section point out the perception from psychology and neuroscience which can be related to NMT –> i do not have any background about these two fields so i skipped (if you have related background — lucky you ^^)


hmmm? another perception from Cognitive Science and Linguistics; i am not interested !!!

ah ha !! RNN we all know about it; so you can read over
Neural Turing Machines
OK here is the beast we need to hunt it down !!!!


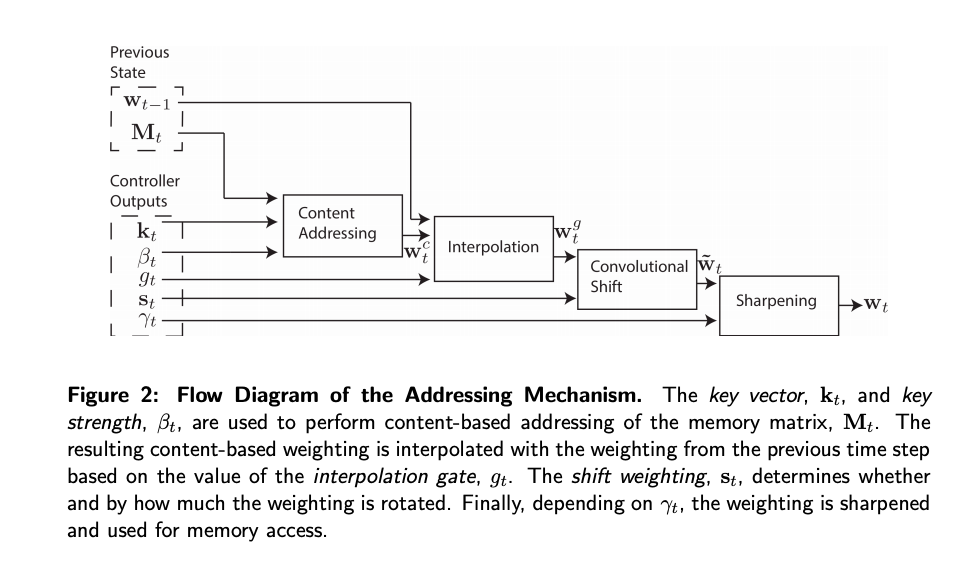
do’t let it scare you; i’m here to help
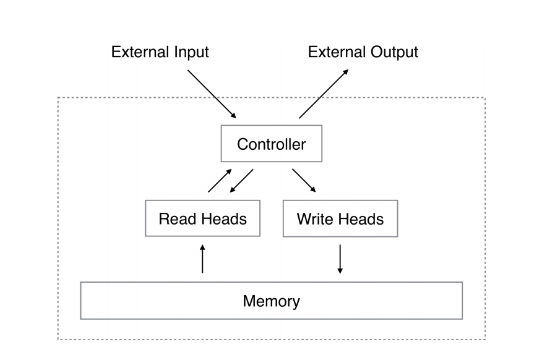
so the description is clear: NTM contains two main component controller and memory bank. Think of memory as 2D matrix which has M row X N columns. And the controller will take the responsibility for reading from and writing to memory bank
Reading
In conventional programming, we access memory by index Mt[i]. But for AI, we access information by similarity. So we derive a reading mechanism using weight. i.e. our result is a weighted sum of our memory.
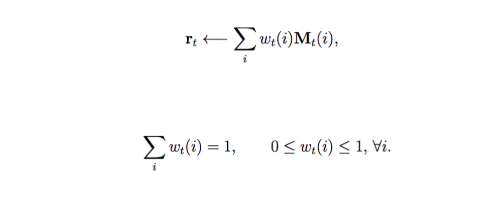
where the sum of all weights equals to one.
You may immediately ask what purpose does it serve. Let’s go through an example. A friend hands you a drink. It tastes very similar to tea and feels creamy like milk. By extracting our memory profile on tea and milk, we apply linear algebra to conclude that it may be a boba tea. Sound like magic. But in word embedding, we use the same kind of linear algebra to manipulate relationships. In other examples like question and answer, it is important to merge information based on accumulated knowledge. A memory network will serve our purpose well.
So how do we create those weights? Of course, it is by deep learning. A controller extracts features (kt) from input and we use it to compute the weights. For example, you take a phone call but you cannot recognize the voice immediately. The voice sounds a whole lot like your cousin but it also resembles the voice of your elder brother. Through linear algebra, we may recognize that it is your high school classmate even though the voice is not what you remember exactly.
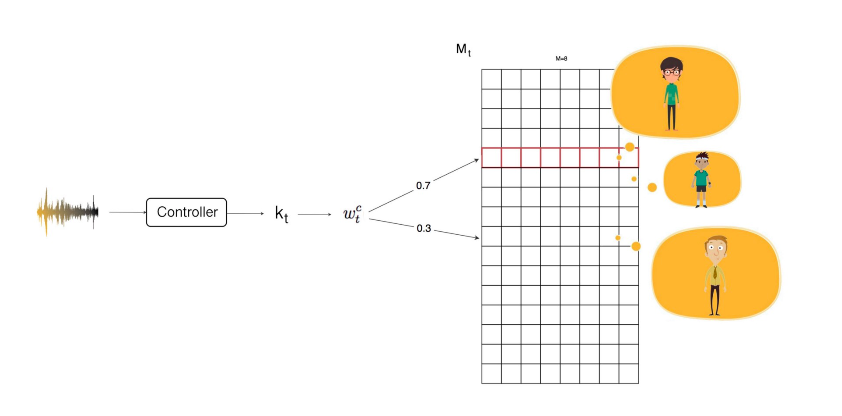
To compute the weight w, we measure the similarity between kt and each of our memory entry. We calculate a score K using cosine similarity.
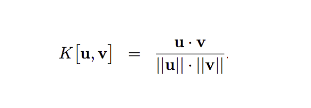
Here, u is our extracted feature kt, and v is each individual rows in our memory.
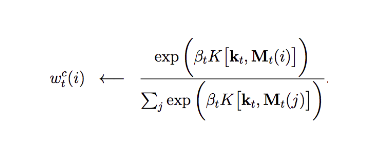
We apply a softmax function on the score K to compute the weight w. βt is added to amplify or attenuate the difference in scores. For example, if it is greater than one, it amplifies the difference. w retrieves information based on similarity and we call this content addressing.
Writing
So how we write information into memory. In LSTM, the internal state of a cell is a combination of the previous state and a new input state. Borrow from the same intuition, the memory writing process composes of previous state and new input. Here, we erase part of the previous state:
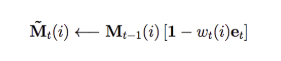
where et is an erase vector. (calculated just like the input gate in LSTM) Then, we write our new information.
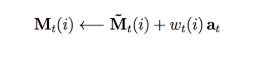
where at is what we want to add. Here, through a controller that generates w, we read and write from our memory.
Addressing Mechanisms
Our controller computes w to extract information. But extraction by similarity (content addressing) is not powerful enough.
Interpolation
w represents what is our current focus (attention) in our memory. In content addressing, our focus is only based on the new input. However, this does not account for our recent encounter. For example, if your classmate texts you an hour ago, you should recall his voice easier. How do we accomplish previous attention in extracting information? We compute a new merged weight based on the current content focus as well as our previous focus. Yes, this sounds like the forget gate in LSTM or GRU.
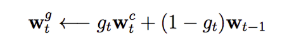
where g is computed from the previous focus and our current input.
Convolution shift
Convolution shifthandles a shift of focus. It is not specifically designed for deep learning. Instead, it shows how a NTM can perform basic algorithms like copying and sorting. For example, instead of accessing w[4], we want to shift every focus by 3 rows. i.e. w[i] ← w[i+3].
In convolution shift, we can shift our focus to a range of rows, i.e. w[i] ← convolution(w[i+3], w[i+4], w[i+5]). Usually, the convolution is just a linear weighted sum of rows 0.3 × w[i+3] + 0.5 × w[i+4] + 0.2 × w[i+5].
This is the mathematical formulation to shift our focus:
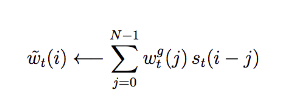
In many deep learning model, we skip this step or set s(i) to 0 except s(0) = 1.
Sharpening
Our convolution shift behaves like a convolutional blurring filter. So we apply sharpening technique to our weights to counter play the blurring if needed. γ will be another parameter output by the controller to sharpen our focus.
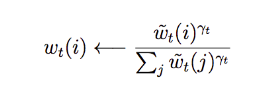
Putting it together
We retrieve information from our memory using the weight w. w includes factors like our current input, previous focus, possible shifting and blurring. Here is the system diagram which a controller outputs the necessary parameters to be used in calculating w at different stages.
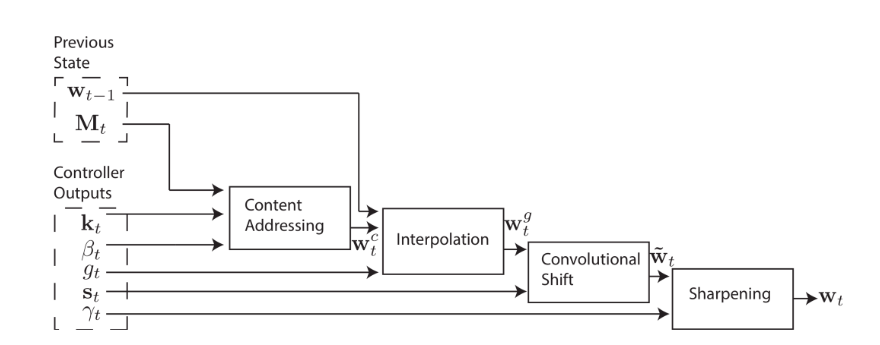
So that’s all about NTM



1 Comment
Recurrent Embedding Dialogue Policy · June 20, 2019 at 12:39 am
[…] Neural Turing Machines […]