Insights from ACL 2019 – questions of the usage of cosine similarity

The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019) spots out some major trends in NLP. This post focus on one exciting and clever paper that motivate the more careful usage of cosine similarity in the word embedding space ” “Correlation Coefficients and Semantic Textual Similarity” [code]”
Introduction
a large body of research focus on how to make better representation of word in term of vector while there is still lack of attention in the manner of comparison. In most of the cases; cosine similarity would be the default choice. The core idea is to consider a word or a sentence embedding as a sample of N observations of some scalar random variable, where N is the embedding size. Then, some classical statistical correlation measures can be applied for pairs of vectors
Correlation Coefficients
In a nutshell, correlation describes how one set of numbers relates to the other, if they then show some relationship, we can use this insight to explore and test causation and even forecast future data. In some extends; correlation can be a good measurement of similarity in stead of traditional cosine. This paper propose some very fundamental correlation metrics such as Pearson, Spearman and Kendall. As their empirical analysis has shown, cosine similarity is equivalent to Pearson’s (linear) correlation coefficient for commonly used word embeddings. It comes from the fact that the values observed in practice are distributed around the zero mean
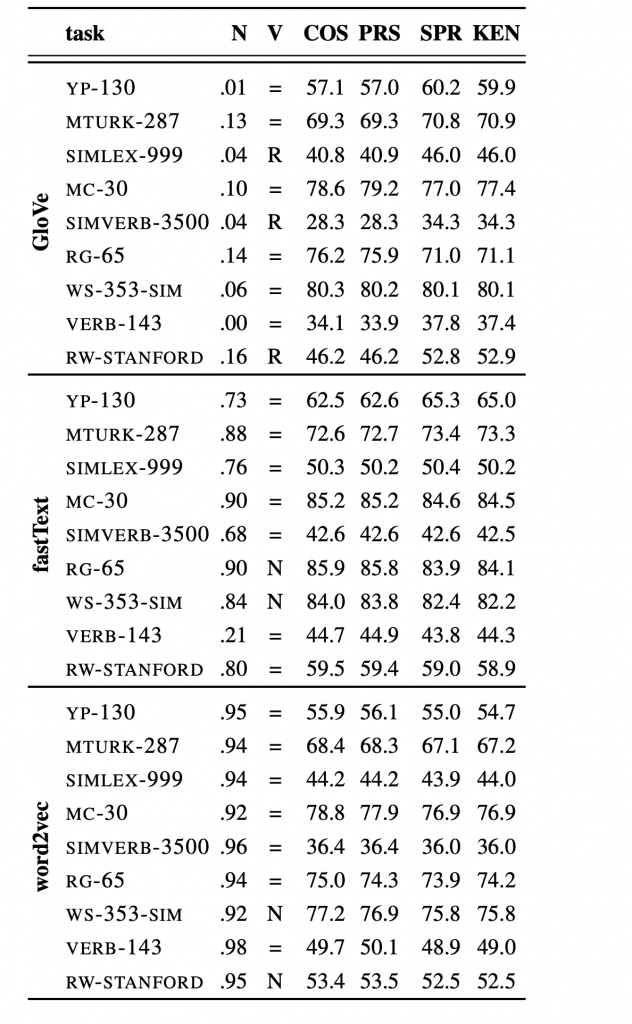
In the scenario of word similarity, a violation of the normality assumption makes cosine similarity especially inappropriate for GloVe vectors. For FastText and word2vec, the results of the Pearson coefficient and rank correlation coefficients (Spearman, Kendall) are comparable. However, the choice of cosine similarity is suboptimal for sentence vectors as centroids of word vectors (a widely used baseline for sentence representation), even for FastText. It is caused by stop word vectors behaving as outliers. The rank correlation measures are empirically preferable in this case
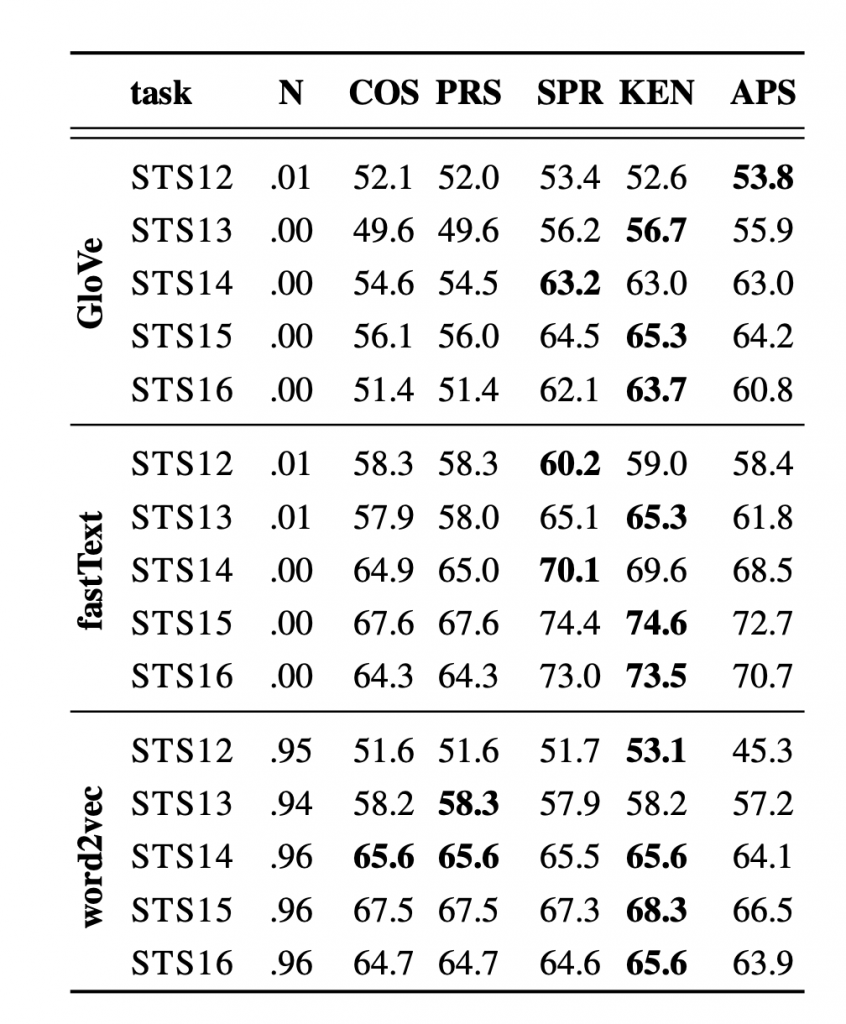
Summary
This paper showed that in common used word vectors, cosine similarity is equivalent to the Pearson correlation coefficient. However in some dataset that the word vectors are not “normal” and the variance is huge there should be an experimental decision for whether or not cosine similarity is a reasonable choice for measuring semantic similarity


