How to take the full control of Rasa Embedding Classifier

Recently, Rasa has adopted the *space (star-space)model from facebook AI research as their main and active maintained intent classifier; This is not a new idea but it shows a very promising results in comparison with various neural architectures such as CNN or RNN in a various kinds of NLP task
In order to tune the embedding intent classifier and take the full control of it; it is essential to understand about the *space idea; what is its architecture; how it is trained and the meaning of the model’s hyper-parameters that Rasa has exposed for us for tuning purpose
Model architecture
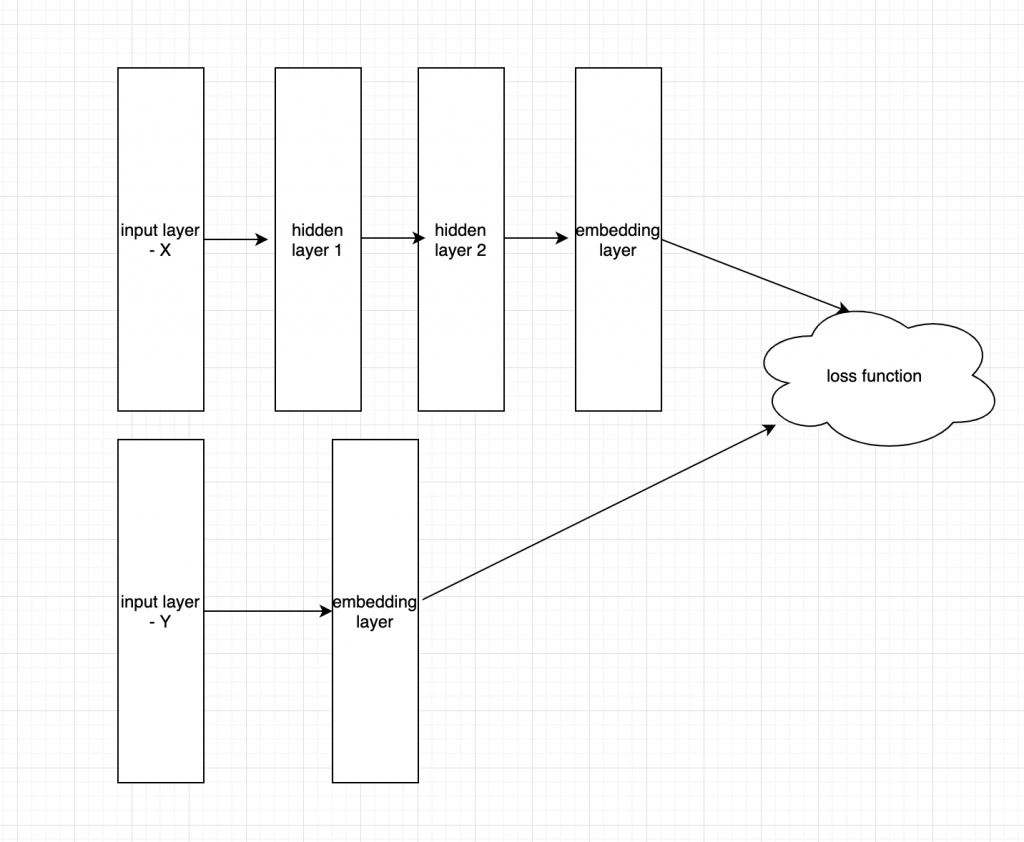
The figure illustrates the architecture of *space neural embedding classifier. Basically, the architecture includes one ore more full-connected hidden layers following by one embedding layer for input and one embedding layer for labels.
Take our problem of intent classifier as an example, we got a dataset including collection of question from user and the corresponding intents. the questions are first tokenizer by space and then transformed to vector format by TF-IDF. The same pre-process algorithm is also applied for intents (so please choose your intent name wisely ^^)
The TF-IDF matrix of question and intents are then feed into two separated natural networks. For the question TF-IDF matrix we often add a couple of hidden layer (2-3 layers) before embedding layer while the labels are normally passed to the embedding layer directly. the dimension of embedding layer is hyper-parameter and we need to specify it by try and errors
The loss function is the dis-similarity of 2 embedding layers calculated by using cosine
==> and that ‘s all the magic behind *space embedding classifier
Model Hyper-parameter
Rasa has exposed some hyper parameter that we can tuning during training the NLU model; all the hyper-parameters are listed in the following link http://rasa.com/docs/rasa/nlu/components/#embeddingintentclassifier
tokenization of intent labels:
intent_tokenization_flagiftruethe algorithm will split the intent labels into tokens and use bag-of-words representations for them, defaultfalse;intent_split_symbolsets the delimiter string to split the intent labels, default_.
the default of intent_tokenization_flag is false it means that we do not tokenize the labels, a good practice is to use _ as a string separator
neural network’s architecture:
hidden_layers_sizes_asets a list of hidden layer sizes before the embedding layer for user inputs, the number of hidden layers is equal to the length of the listhidden_layers_sizes_bsets a list of hidden layer sizes before the embedding layer for intent labels, the number of hidden layers is equal to the length of the list
hidden_layers_sizes_a is the number of hidden layer and the number units in each hidden layer of input, the default value is [256,128] meaning 2 hidden layers, the first layer contains 256 unit, the second layer contains 128 unit
hidden_layers_sizes_b s the number of hidden layer and the number units in each hidden layer of label, the default value is [] meaning labels are passed directly to embedding layer
training:
batch_sizesets the number of training examples in one forward/backward pass, the higher the batch size, the more memory space you’ll need;epochssets the number of times the algorithm will see training data, whereoneepoch= one forward pass and one backward pass of all the training examples;
the current default batch size is [64,128] this is call linear batch size increasing; the basic idea is that in stead of learning rate decay we can increase the batch size of training data
for example if we config batch_size is [64,128] and the number of epochs are 100 we would got the number of addition batch is (128-64)//100 over one epoch
if we got small data we should keep batch size in the range of [8,32], when the data is large we can think of batch size of [64,256] the batch size should not be over 256
epochs: the number of training iteration, the default is 300
embedding:
embed_dimsets the dimension of embedding space;mu_poscontrols how similar the algorithm should try to make embedding vectors for correct intent labels;mu_negcontrols maximum negative similarity for incorrect intents;similarity_typesets the type of the similarity, it should be eithercosineorinner;num_negsets the number of incorrect intent labels, the algorithm will minimize their similarity to the user input during training;use_max_sim_negiftruethe algorithm only minimizes maximum similarity over incorrect intent labels;random_seed(None or int) An integer sets the random seed for numpy and tensorflow, so that the random initialisation is always the same and produces the same training result
embed_dim: is the dimension of embedding layer, the value of embedding layer is typical 10-300, the current value is 20, the larger embedding dimension the more possible for overfitting, do not use dimension > 50 unless you got a ton of data
mu_pos: the target cosine for similarity, currently its value is 0.8 you can change it to 1.0 if you need strict similarity or 0.7->0.6 for hard data
mu_neg: target cosine for dis-similarity; the default value is -0.4, and you can adjust it from -1.0 to 0
num_neg: the number of negative sample corresponding to positive sample
regularization:
C2sets the scale of L2 regularizationC_embsets the scale of how important is to minimize the maximum similarity between embeddings of different intent labels;dropratesets the dropout rate, it should be between0and1, e.g.droprate=0.1would drop out10%of input units;
regularization parameters controls the generality of model,
c2: is set to 0.002 in default, you can increase this number to penalize model for overfiting (c2 is L2 regularization)
C_emb: the default value if 0.8, this prevent overfitting of 2 embedding layer, you can increase this number if the network is not genral
droprate: default is 0.1, the typical value for droprate ranges from 0.1 to 0.5, the larger value the more general model
==> adjusting these hyper-parameters are called model tuning:D
HAPPY TUNING
REF:
*Space: https://arxiv.org/pdf/1709.03856.pdf
Linear batch size increasing: https://arxiv.org/pdf/1711.00489.pdf



1 Comment
Pham Hung · June 13, 2019 at 2:59 pm
Great article ! Thank to author <3