Intro to NLP
NLP Overview
Welcome to Natural Language Processing. Language is an important medium for human communication. It allows us to convey information, express our ideas, and give instructions to others. Some philosophers argue that it enables us to form complex thoughts and reason about them. It may turn out to be a critical component of human intelligence. Now consider the various artificial systems we interact with every day, phones, cars, websites, coffee machines. It’s natural to expect them to be able to process and understand human language, Yet, computers are still lagging behind. No doubt, we have made some incredible progress in the field of natural language processing, but there is still a long way to go. And that’s what makes this an exciting and dynamic area of study.
Structured Languages
What makes it so hard for computers to understand us? One drawback of human languages, or feature depending on how you look at it, is the lack of a precisely defined structure. To understand how that makes things difficult let’s first take a look at some languages that are more structured. Mathematics, for instance, uses a structured language. When I write y equals 2x plus 5 there is no ambiguity in what I want to convey. I’m saying that the variable y is related to the variable x as two times x plus five.

Consider this SQL statement. SELECT name, email FROM users WHERE name LIKE A% We are asking the database to return the names and e-mail addresses of all users whose names begin with an A. These languages are designed to be as unambiguous as possible and are suitable for computers to process.

Unstructured Text
The languages we use to communicate with each other also have defined grammatical rules. And indeed, in some situations we use simple structured sentences but for the most part human discourse is complex and unstructured. Despite that, we seem to be really good at understanding each other and even ambiguities are welcome to a certain extent. So, what can computers do to make sense of unstructured text? Here are some preliminary ideas. Computers can do some level of processing with words and phrases, trying to identify key words, parts of speech, named entities, dates, quantities, etc.

Using this information they can also try to parse sentences, at least ones that are relatively more structured.

This can help extract the relevant parts of statements, questions, or instructions. At a higher level computers can analyze documents to find frequent and rare words, assess the overall tone or sentiment being expressed, and even cluster or group similar documents together. You can imagine that building on top of these ideas, computers can do a whole lot with unstructured text even if they cannot understand it like us.

Context Is Everything
So what is stopping computers from becoming as capable as humans in understanding natural language? Part of the problem lies in the variability and complexity of our sentences. Consider this excerpt from a movie review. “I was lured to see this on the promise of a smart witty slice of old fashioned fun and intrigue. I was conned. ”

Although it starts with some potentially positive words it turns out to be a strongly negative review. Sentences like this might be somewhat entertaining for us but computers tend to make mistakes when trying to analyze them. But there is a bigger challenge that makes NLP harder than you think. Take a look at this sentence “The sofa didn’t fit through the door because it was too narrow.”

What does “it” refer to? Clearly “it” refers to the door.
Now consider a slight variation of this sentence. “The sofa didn’t fit through the door because it was too wide.” What does “it” refer to in this case? Here it’s the sofa. Think about it. To understand the proper meaning or semantics of the sentence you implicitly applied your knowledge about the physical world, that wide things don’t fit through narrow things.

NLP and Pipelines
Natural language processing is one of the fastest growing fields in the world. NLP Is making its way into a number of products and services that we use every day. Let’s begin with an overview of how to design an end-to-end NLP pipeline.

Not that kind of pipeline; a natural language processing pipeline, where you start with raw text, in whatever form it is available, process it, extract relevant features, and build models to accomplish various NLP tasks. Now that I think about it, that is kind of like refining crude oil. Anyways, you’ll learn how these different stages in the pipeline depend on each other. You’ll also learn how to make design decisions, how to choose existing libraries, and tools to perform each step.
How NLP Pipelines Work
Let’s look at a common NLP pipeline. It consists of three stages, text processing, feature extraction and modeling.
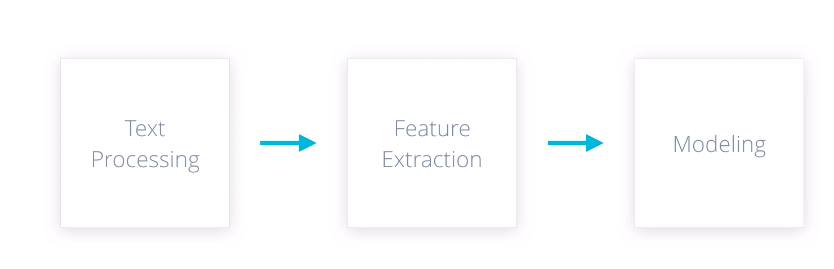
Each stage transforms text in some way and produces a result that the next stage needs. For example, the goal of text processing is to take raw input text, clean it, normalize it, and convert it into a form that is suitable for feature extraction. Similarly, the next stage needs to extract and produce feature representations that are appropriate for that type of model you’re planning to use and the NLP task you’re trying to accomplish. When you’re building such a pipeline, your workflow may not be perfectly linear. Let’s say, you spend some time implementing text processing functions, then make some simple feature extractors, and then design a baseline statistical model. But then, maybe you are not happy with the results. So you go back and rethink what features you need, and that in turn, can make you change your processing routines. Keep in mind that this is a very simplified view of natural language processing. Your application may require additional steps.
Text Processing
Let’s take a closer look at text processing. The first question that comes to mind is, why do we need to process text? Why can we not feed it in directly? To understand that, think about where we get this text to begin with.

Websites are a common source of textual information. Here’s a portion of a sample web page from Wikipedia and the corresponding HTML markup, which serves as our raw input. For the purpose of natural language processing, you would typically want to get rid of all or most of the HTML tags, and retain only plain text.
You can also remove or set aside any URLs or other items not relevant to your task. The Web is probably the most common and fastest growing source of textual content. But you may also need to consume PDFs, Word documents or other file formats. Or your raw input may even come from a speech recognition system or from a book scan using OCR. Some knowledge of the source medium can help you properly handle the input. In the end, your goal is to extract plain text that is free of any source specific markers or constructs that are not relevant to your task.

Once you have obtained plain text, some further processing may be necessary. For instance, capitalization doesn’t usually change the meaning of a word. We can convert all the words to the same case so that they’re not treated differently.

Punctuation marks that we use to indicate pauses, etc. can also be removed. Some common words in a language often help provide structure, but don’t add much meaning. For example, a, and, the, of, are, and so on.

Sometimes it’s best to remove them if that helps reduce the complexity of the procedures you want to apply later.
Feature Extraction
Okay. We now have clean normalized text. Can we feed this into a statistical or a machine learning model? Not quite. Let’s see why. Text data is represented on modern computers using an encoding such as ASCII or Unicode that maps every character to a number. Computer store and transmit these values as binary, zeros and ones. These numbers also have an implicit ordering. 65 is less than 66 which is less than 67. But does that mean A is less than B, and B is less and C? No. In fact, that would be an incorrect assumption to make and might mislead our natural language processing algorithms.

Moreover, individual characters don’t carry much meaning at all. It is words that we should be concerned with, but computers don’t have a standard representation for words. Yes, internally they are just sequences of ASCII or Unicode values but they don’t quite capture the meanings or relationships between words. Compare this with how an image is represented in computer memory. Each pixel value contains the relative intensity of light at that spot in the image. For a color image, we keep one value per primary color; red, green, and blue. These values carry relevant information. Two pixels with similar values are perceptually similar. Therefore, it makes sense to directly use pixel values in a numerical model.
So the question is, how do we come up with a similar representation for text data that we can use as features for modeling? The answer again depends on what kind of model you’re using and what task you’re trying to accomplish. If you want to use a graph based model to extract insights, you may want to represent your words as symbolic nodes with relationships between them like WordNet.
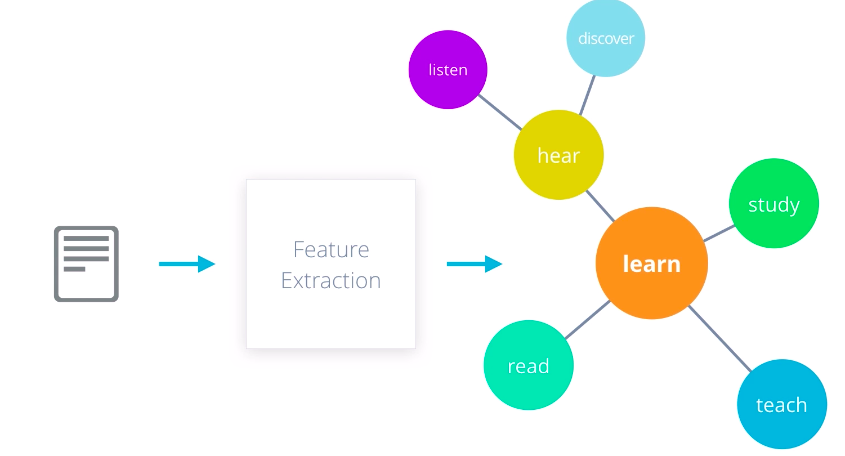
For statistical models however, you need some sort of numerical representation. Even then, you have to think about the end goal. If you’re trying to perform a document level task, such as spam detection or sentiment analysis, you may want to use a per document representations such as bag-of-words or doc2vec.

If you want to work with individual words and phrases such as for text generation or machine translation, you’ll need a word level representation such as word2vec or glove. There are many ways of representing textual information, and it is only through practice that you can learn what you need for each problem.
Modeling
The final stage in this process is what I like to call modeling. This includes designing a model, usually a statistical or a machine learning model, fitting its parameters to training data using an optimization procedure, and then using it to make predictions about unseen data.
The nice thing about working with numerical features is that it allows you to utilize pretty much any machine learning model. This includes support vector machines, decision trees, neural networks, or any custom model of your choice You could even combine multiple models to get better performance
How you utilize the model is up to you. You can deploy it as a web-based application, package it up into a handy mobile app, integrate it with other products,

The possibilities are endless.


