Text Processing
In this post, you’ll learn how to read text data from different sources and prepare it for feature extraction. You’ll begin by cleaning it to remove irrelevant items, such as HTML tags.

You will then normalize text by converting it into all lowercase, removing punctuations and extra spaces.

Next, you will split the text into words or tokens and remove words that are too common, also known as stop words.

Finally, you will learn how to identify different parts of speech, named entities, and convert words into canonical forms using stemming and lemmatization.

After going through all these processing steps, your text may look very different, but it captures the essence of what was being conveyed in a form that is easier to work with.
Capturing Text Data
The processing stage begins with reading text data. Depending on your application, that can be from one of several sources. The simplest source is a plain text file on your local machine. We can read it in using Python’s built in file input mechanism.

Text data may also be included as part of a larger database or table. Here, we have a CSV file containing information about some news articles. We can read this in using pandas very easily. Pandas includes several useful string manipulation methods that can be applied to an entire column at once. For instance, converting all values to lowercase.

Sometimes, you may have to fetch data from an online resource, such as a web service or API. In this example, we use the requests library in Python to obtain a quote of the day from a simple API, but you could also obtain tweets, reviews, comments, whatever you would like to analyze. Most APIs return JSON or XML data, so you need to be aware of the structure in order to pull out the fields that you need. Many data sets you will encounter have likely been fetched and prepared by someone else using a similar procedure.

Normalization
Plain text is great but it’s still human language with all its variations and bells and whistles. Next, we’ll try to reduce some of that complexity. In the English language, the starting letter of the first word in any sentence is usually capitalized. All caps are sometimes used for emphasis and for stylistic reasons. While this is convenient for a human reader from the standpoint of a machine learning algorithm, it does not make sense to differentiate between Car, car, and CAR, they all mean the same thing.
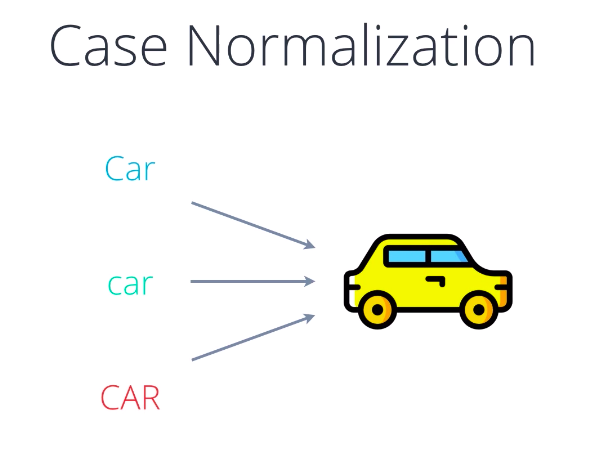
Therefore, we usually convert every letter in our text to a common case, usually lowercase, so that each word is represented by a unique token. Here’s some sample text, a review for the movie, The Second Renaissance, a story about intelligent robots that get into a fight with humans over their rights. Anyway, if we have the reviews stored in a variable called text, converting it to lowercase is a simple call to the lore method in Python. Here’s what it looks like after a conversion. Note all the letters that were changed. Other languages may or may not have a case equivalent but similar principles may apply depending on your NLP task, you may want to remove special characters like periods, question marks, and exclamation points from the text and only keep letters of the alphabet and maybe numbers.

This is especially useful when we are looking at text documents as a whole in applications like document classification and clustering where the low level details do not matter a lot. Here, we can use a regular expression that matches everything that is not a lowercase A to Z, uppercase A is Z, or digits zero to nine, and replaces them with a space. This approach avoids having to specify all punctuation characters, but you can use other regular expressions as well. Lowercase conversion and punctuation removal are the two most common text normalization steps.

Whether you need to apply them and at what stage depends on your end goal and the way you design your pipeline.
Tokenization
Token is a fancy term for a symbol. Usually, one that holds some meaning and is not typically split up any further. In case of natural language processing, our tokens are usually individual words. So tokenization is simply splitting each sentence into a sequence of words. The simplest way to do this is using the split method which returns a list of words. Note that it splits on whitespace characters by default, which includes regular spaces but also tabs, new lines, et cetera. It’s also smart about ignoring two or more whitespace characters in a sequence, so it doesn’t return blank strings.

But you can control all this using optional parameters. So far, we’ve only been using Python’s built-in functionality, but some of these operations are much easier to perform using a library like NLTK, which stands for natural language toolkit. The most common approach for splitting up texting NLTK is to use the word tokenized function from nltk.tokenize.

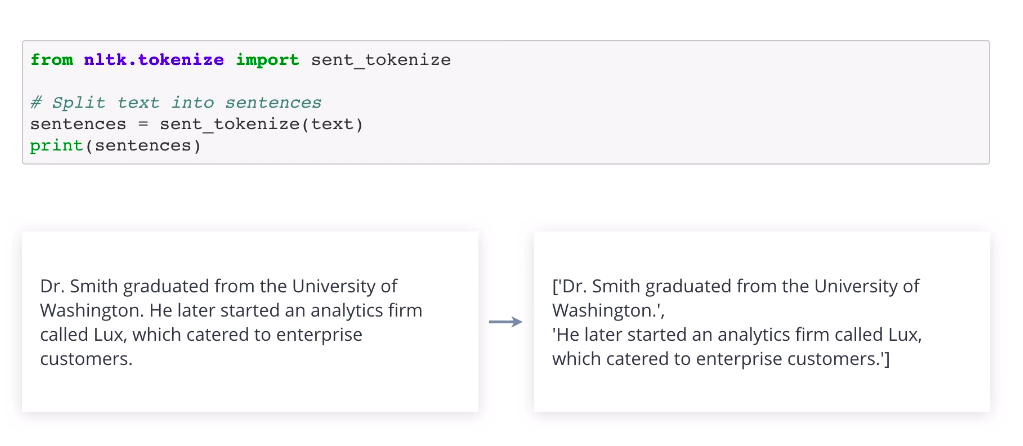
This performs the same task as split but is a little smarter. Try passing in some raw text that has not been normalized. You’ll notice that the punctuations are treated differently based on their position. Here, the period after the title Doctor has been retained along with Dr as a single token. As you can imagine, NLTK is using some rules or patterns to decide what to do with each punctuation. Sometimes, you may need to split text into sentences. For instance, if you want to translate it. You can achieve this with NLTK using sent tokenize. Then you can split each sentence into words if needed.
NLTK provide several other tokenizers, including a regular expression base tokenizer that you can use to remove punctuation and perform tokenization in a single step, and also a tweet tokenizer that is aware of twitter handles, hash tags, and emoticons.
Stop Word Removal
Stop words are uninformative words like, is, our, the, in, at, et cetera that do not add a lot of meaning to a sentence.

They are typically very commonly occurring words, and we may want to remove them to reduce the vocabulary we have to deal with and hence the complexity of later procedures. Notice that even without our and the in the sentence above, we can still infer it’s positive sentiment toward dogs. You can see for yourself which words NLTK considers to be stop words in English. Note that this is based on a specific corpus or collection of text. Different corpora may have different stop words.

Also, a word maybe a stop word in one application, but a useful word in another. To remove stop words from a piece of text, you can use a Python list comprehension with a filtering condition.
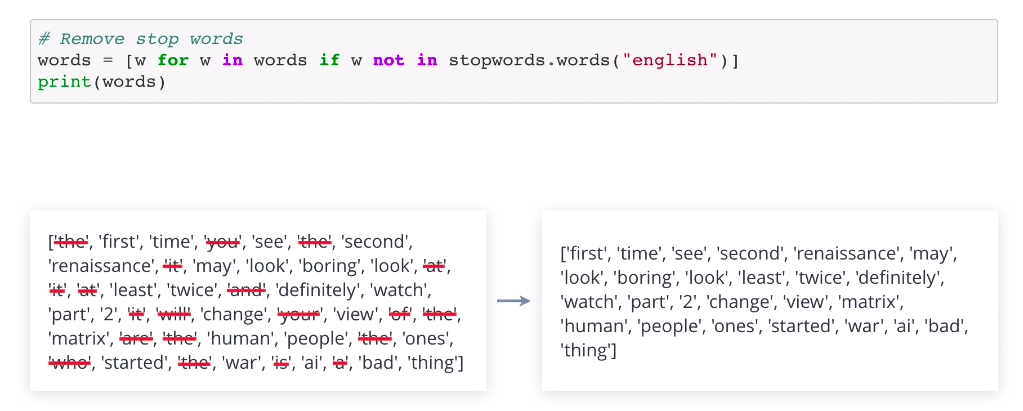
Here, we apply stop word removal to the movie review after normalizing and tokenizing it. The result is a little hard to read, but notice how it has helped reduce the size of the input, at the same time important words have been retained.
Part-of-Speech Tagging
Remember parts of speech from school? Nouns, pronouns, verbs, adverbs, etc ….. Identifying how words are being used in a sentence can help us better understand what is being said.

It can also point out relationships between words and recognize cross references. NLTK, again, makes things pretty easy for us. You can pass in tokens or words to the POS tag function which returns a tag for each word identifying different parts of speech. Notice how it has correctly labelled the first utterance of “lie” as a verb, while marking the second one as a noun.

Refer to the NLTK documentation for more details on what each tag means. One of the cool applications of part of speech tagging is parsing sentences. Here’s an example from the NLTK book that uses a custom grammar to parse an ambiguous sentence.

Named Entity Recognition
Named entities are typically noun phrases that refer to some specific object, person, or place. You can use the ne_chunk function to label named entities in text. Note that you have to first tokenize and tag parts of speech. This is a very simple example but notice how the different entity types are also recognized: person, organization, and GPE, which stands for geopolitical entity. Also note how it identified the two words, Udacity and Inc, together as a single entity.

Out in the wild, performance is not always great but training on a large corpus definitely helps. Named entity recognition is often used to index and search for news articles, for example, on companies of interest.
Stemming and Lemmatization
In order to further simplify text data, let’s look at some ways to normalize different variations and modifications of words. Stemming is the process of reducing a word to its stem or root form. For instance, branching, branched, branches et cetera, can all be reduced to branch.
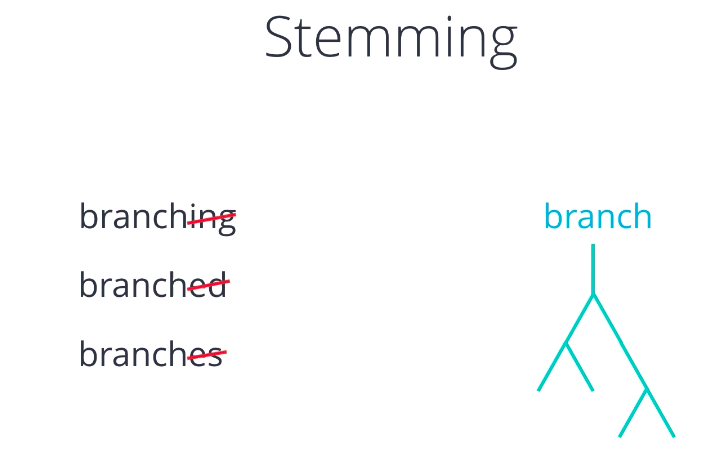
After all, they conveyed the idea of something separating into multiple paths or branches. Again, this helps reduce complexity while retaining the essence of meaning that is carried by words. Stemming is meant to be a fast and crude operation carried out by applying very simple search and replace style rules. For example, the suffixes ‘ing’ and ‘ed’ can be dropped off, ‘ies’ can be replaced by ‘y’ et cetera. This may result in stem words that are not complete words, NLTK has a few different stemmers for you to choose from, including PorterStemmer that we use here, SnowballStemmer, and other language-specific stemmers.

Lemmatization is another technique used to reduce words to a normalized form, but in this case, the transformation actually uses a dictionary to map different variants of a word back to its root. With this approach, we are able to reduce non-trivial inflections such as is, was, were, back to the root ‘be’.
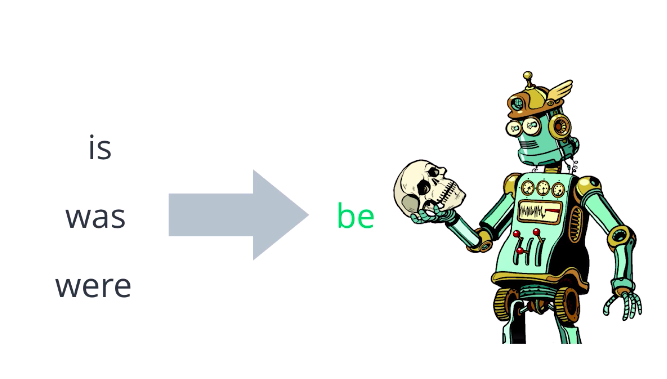
The default lemmatizer in NLTK uses the Wordnet database to reduce words to the root form. Let’s try it out.

Lemmatization is similar to stemming with one difference, the final form is also a meaningful word. That said, stemming does not need a dictionary like lemmatization does. So depending on the constraints you have, stemming maybe a less memory intensive option for you to consider.

Summary
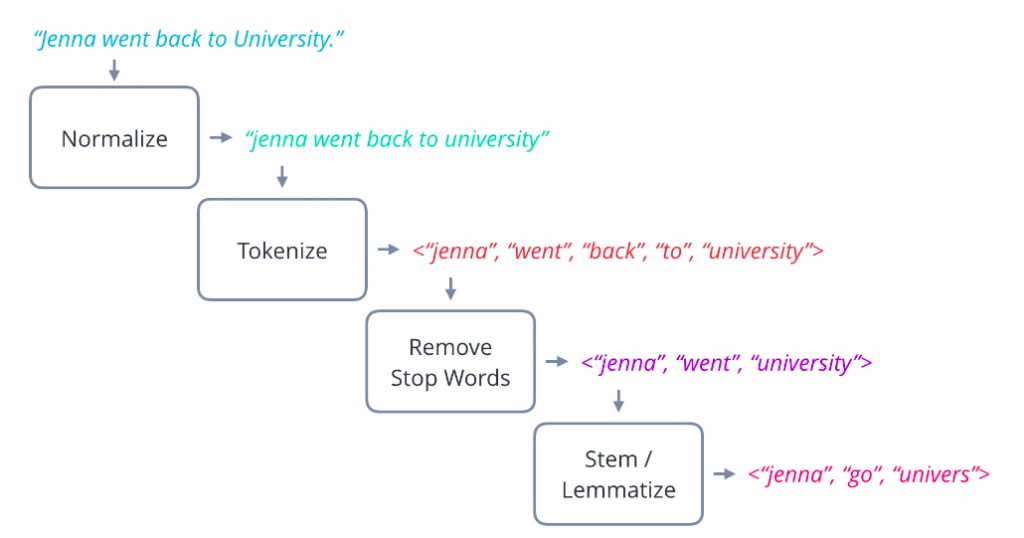
We have covered a number of text processing steps. Let’s summarize what a typical workflow looks like. Starting with a plain text sentence, you first normalize it by converting to lowercase and removing punctuation, and then you split it up into words using a tokenizer. Next, you can remove stop words to reduce the vocabulary you have to deal with. Depending on your application, you may then choose to apply a combination of stemming and lemmatization to reduce words to the root or stem form. It is common to apply both, lemmatization first, and then stemming. This procedure converts a natural language sentence into a sequence of normalized tokens which you can use for further analysis.
Practical Notebook for text processing can be found at http://14.232.166.121:8880/lab/workspaces/andy > text_processing.ipnyb


