Neural Machine Translation, Seq2seq

there’s a whole class of NLP tasks that rely on sequential output, or outputs that are sequences of potentially varying length. For example:
- Translation: taking a sentence in one language as input and outputting the same sentence in another language.
- Conversation: taking a statement or question as input and responding to it.
- Summarization: taking a large body of text as input and outputting a summary of it.
In these post, we’ll look at sequence-to-sequence models, a deep learning-based framework for handling these types of problems. This framework proved to be very effective, and has, in fewer than 3 years, become the standard for machine translation.
Sequence-to-sequence Basics
Sequence-to-sequence, or “Seq2Seq”, is a relatively new paradigm, with its first published usage in 2014 for English-French translation . At a high level, a sequence-to-sequence model is an end-to-end model made up of two recurrent neural networks:
- an encoder, which takes the model’s input sequence as input and encodes it into a fixed-size “context vector”, and
- a decoder, which uses the context vector from above as a “seed” from which to generate an output sequence. For this reason, Seq2Seq models are often referred to as “encoder-decoder models.” We’ll look at the details of these two networks separately
Seq2Seq architecture — encoder
The encoder network’s job is to read the input sequence to our Seq2Seq model and generate a fixed-dimensional context vector C for the sequence. To do so, the encoder will use a recurrent neural network cell — usually an LSTM — to read the input tokens one at a time. The final hidden state of the cell will then become C. However, because it’s so difficult to compress an arbitrary-length sequence into a single fixed-size vector (especially for difficult tasks like translation), the encoder will usually consist of stacked LSTMs: a series of LSTM “layers” where each layer’s outputs are the input sequence to the next layer. The final layer’s LSTM hidden state will be used as C.
Seq2Seq encoders will often do something strange: they will process the input sequence in reverse. This is actually done on purpose. The idea is that, by doing this, the last thing that the encoder sees will (roughly) corresponds to the first thing that the model outputs; this makes it easier for the decoder to “get started” on the output, which makes then gives the decoder an easier time generating a proper output sentence. In the context of translation, we’re allowing the network to translate the first few words of the input as soon as it sees them; once it has the first few words translated correctly, it’s much easier to go on to construct a correct sentence than it is to do so from scratch. See the following for an example of what such an encoder network might look like.
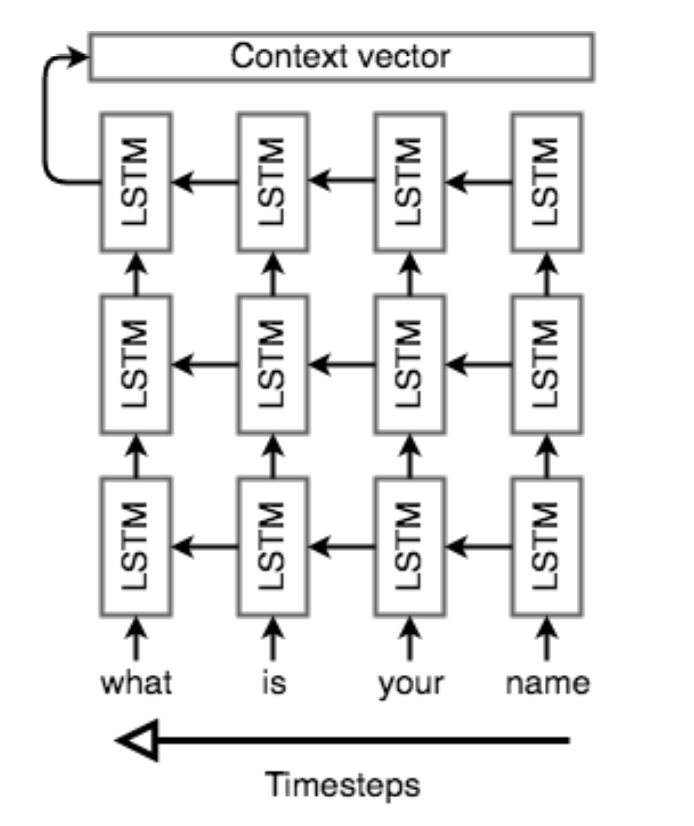
Seq2Seq architecture — decoder
The decoder is also an LSTM network, but its usage is a little more complex than the encoder network. Essentially, we’d like to use it as a language model that’s “aware” of the words that it’s generated so far and of the input. To that end, we’ll keep the “stacked” LSTM architecture from the encoder, but we’ll initialize the hidden state of our first layer with the context vector from above; the decoder will literally use the context of the input to generate an output. Once the decoder is set up with its context, we’ll pass in a special token to signify the start of output generation; in literature, this is usually an token appended to the end of the input (there’s also one at the end of the output). Then, we’ll run all three layers of LSTM, one after the other, following up with a softmax on the final layer’s output to generate the first output word. Then, we pass that word into the first layer, and repeat the generation. This is how we get the LSTMs to act like a language model. See the following figure for an example of a decoder network. Once we have the output sequence, we use the same learning strategy as usual. We define a loss, the cross entropy on the prediction sequence, and we minimize it with a gradient descent algorithm and back-propagation. Both the encoder and decoder are trained at the same time, so that they both learn the same context vector representation.
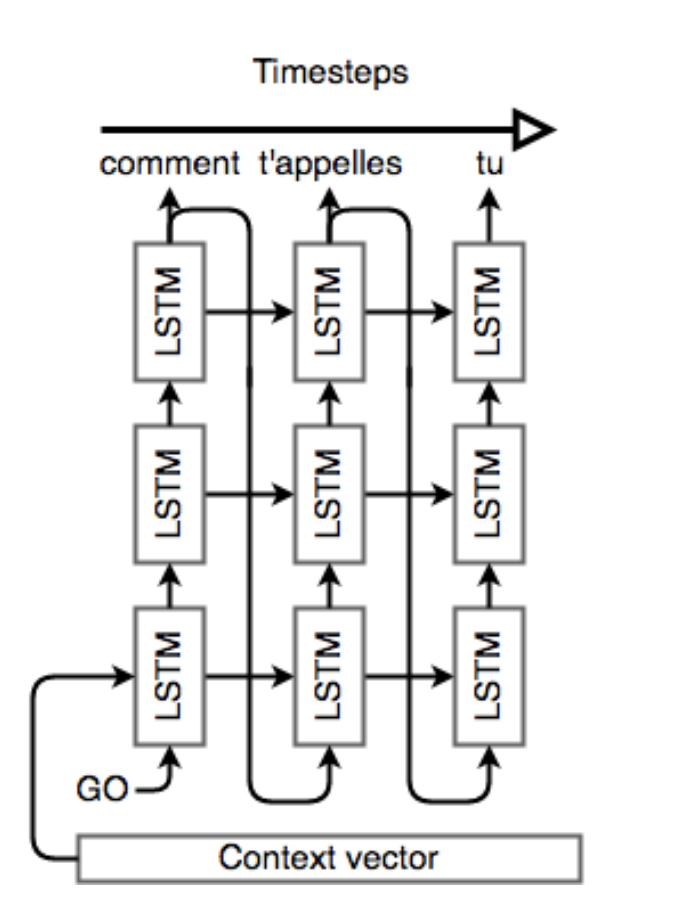
Recap & Basic NMT Example
Note that there is no connection between the lengths of the input and output; any length input can be passed in and any length output can be generated. However, Seq2Seq models are known to lose effectiveness on very long inputs, a consequence of the practical limits of LSTMs. To recap, let’s think about what a Seq2Seq model does in order to translate the English “what is your name” into the French “comment t’appelles tu”. First, we start with 4 one-hot vectors for the input. These inputs may or may not (for translation, they usually are) embedded into a dense vector representation. Then, a stacked LSTM network reads the sequence in reverse and encodes it into a context vector. This context vector is a vector space representation of the notion of asking someone for their name. It’s used to initialize the first layer of another stacked LSTM. We run one step of each layer of this network, perform softmax on the last layer’s output, and use that to select our first output word. This word is fed back into the network as input, and the rest of the sentence “comment t’appelles tu” is decoded in this fashion. During back-propagation, the encoder’s LSTM weights are updated so that it learns a better vector space representation for sentences, while the decoder’s LSTM weights are trained to allow it to generate grammatically correct sentences that are relevant to the context vector.


