Sequential NLP and memory – part 1

In this blog series we will discuss about Question Answering: answering a question on the basis of a number of facts. This task involves using memory: facts are stored in memory, and the question refers back to past information. How do the various models for sequential processing stack up to this task?
We will demonstrate the difference between “flat memory” approaches like RNNs and LTSMs,
and “responsive memory” approaches like end-to-end memory networks in the context of
Question Answering, and we will assess the benefits of memory networks for question
answering
Memory and language
Language is a sequential, contextual phenomenon, and often addresses long range dependencies, which must be kept in memory when emerging, and be available at later time steps for analysis. Examples are part-of-speech tagging, syntactic parsing, sentiment and topic analysis and semantic role labeling. For example, in order to assign the correct part of speech (a verb, not a noun) to ‘man’ in the following confusing, so-called garden path sentence , the use of context (both to the left and right of ‘man’) is crucial:
- The old man the boat
Another memory-intensive task is Question-Answering: answering a question on the basis of a
preceding sequence of facts.
Question Answering involves matching answers (like factual statements) to questions. In a
machine learning context, this means teaching a machine to associate answers to questions.
Especially in the case of having several independent pieces of information available that may or
may not be relevant for answering a question, this task becomes dependent on memory: keeping information in memory and being able to revert to that stored information.
An example of such a case would be:

The answer to the question in sentence 3 depends on fact 1. Facts 1 and 2 together are called a
story or a context. Fact 2 is an irrelevant fact for answering the question. A machine learning
model learning these relations must have the capacity to store both facts, since, at encountering these facts, it does not know the upcoming question
Let’s address the problem we are trying to solve by means of a scenario.
Scenario: You are working on a language understanding module for a chatbot. The chatbot must be able to answer questions about historical facts you hand it through a chat window: it must be able to refer back to older information in order to answer a question. Specifically, every question can be answered by exactly one statement that occurred in the past. You have at hand a large dataset of hand-annotated questions linked to supporting facts, and a set of candidate architectures that allow you to reason about memory. Using RNN, LSTM, and end-to-end memory networks, how can you implement this chatbot module?
So, the problem boils down to this: given a sequence of sentences, and a question that can be answered by one (and only one) of the sentences, how can we retrieve the necessary information for answering the question? Clearly, we have no idea what specific fragment of which sentence is holding the answer. So, we need to store all information in these sentences (the ) and be story able to get back to that information when the question pops up. The limitation to one sentence holding the answer to our question means we address ‘single-fact question answering’ as apposed to multi-fact question-answering
Data and data processing
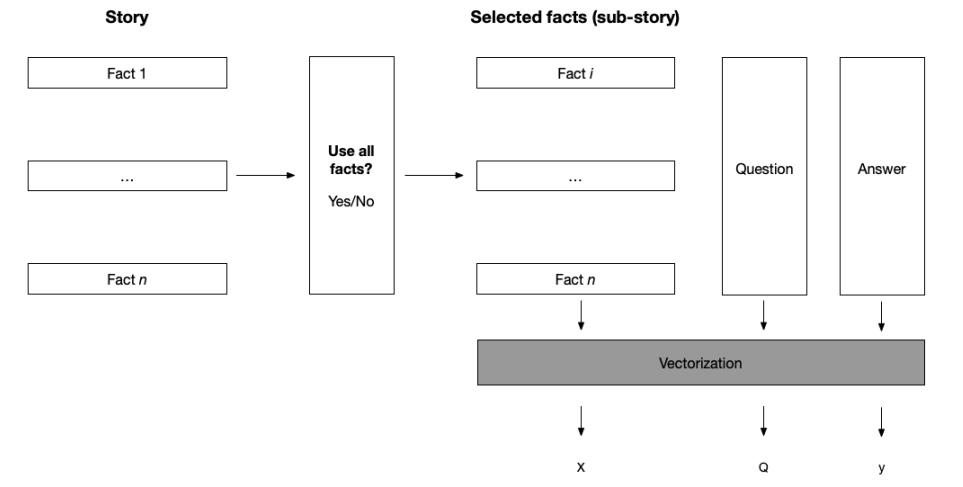
We will use data produced by Facebook, called the bAbI dataset . This dataset consists of sequences of facts, linked to questions. One or more of the facts hold the answer to the question. The dataset comprises a set of question-answering tasks, where, often, the link between the facts holding the answers and the question is remote: typically, many irrelevant facts intervene between question and answer. See below for typical data. A list of facts (numbered sentences) is followed by a question, an answer to that question (just one word), and the identifier of the sentence holding the answer.

A sequence like this is called a in bAbI. Storing all intervening context story
between a question and the sentence holding its answer clearly poses a burden on the memory
capacity of models. We will investigate the performance of our models under two conditions:
- Only using a question and the supporting fact.
- Using all facts in a story, also non-relevant ones for answering a particular question.
The first condition can be used to assess question-answer matching in a restricted manner, and the second condition addresses picking out an answer from a large heap of unrelated data, demanding much more memory storage. How well do our models stack up to these conditions Let’s first develop procedures for getting the bAbI data ready for our models, by turning it into vector representations.
We will convert stories into ordered lists of vectors and train a network to learn the relationship between a question and a word in one of the facts. This means we are modeling a (possibly long-distance) dependency. The actual deep learning part of this procedure is outlined in the next sections, where we discuss different models
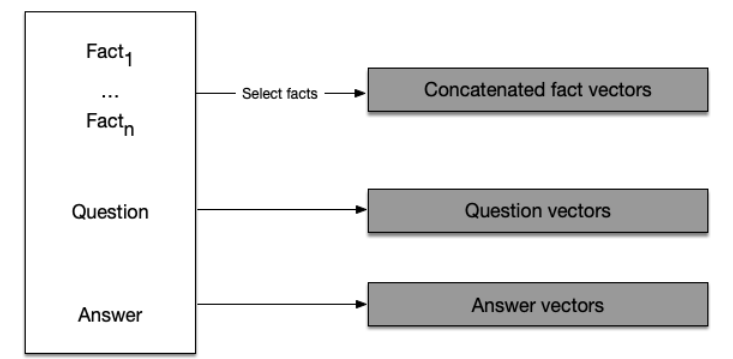
We will need to create three lists of vectors, the reasons for which will become apparent soon.
- First, we need a list holding all facts as vectors.
- Secondly, we need a list of vectorized questions.
- Thirdly, we need a list of labels: word indices referring to the word that is the answer to a question.
For starters, we need a procedure for converting the bAbI stories to vectors. The first step in this process is to create a tokenizer. With the generated tokenizer at hand, we can process our bAbI stories. We represent every list of facts (either including intervening, irrelevant facts or just the fact(s) holding the answer to the question) as one big vector. So, we basically concatenate the entire list of facts to one big string, and tokenize that string (convert it to a numerical vector). This is a rather crude data representation, but it turns out to work out well on average, as we will see shortly.
RNNs for Question Answering
We will implement a branching model, with two RNNs The two RNNs handle respectively the facts (stories) and the question. Their output is merged by concatenation, and sent through a Dense layer that produces a scalar of the size of our answer vocabulary, consisting of probabilities. The model is seeded with answer vectors with one bit on (one-hot), so the highest probability in the output layer reflects the most probable bit, indicating a unique answer word in our lexicon
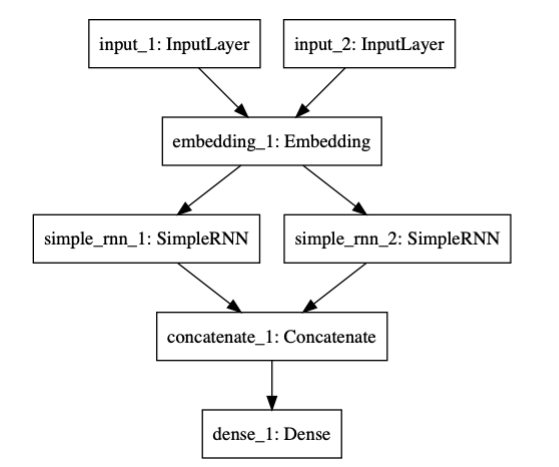
The idea behind the branching model is that we combine two temporal processes: one for
analyzing a story, and one for analyzing a question. The questions are uniformly short sequences in the bAbI task (they consist of just 3 words); the stories can be quite long: up to 58 words in this task. We will use a single embedding for embedding both stories and questions; you can also experiment with separate embeddings
Experiment
We start off with training the model without intervening irrelevant context. This works out
perfectly. The RNN, simple as it is, learns the association of the single fact vector, the question
vector , and the single-word answer index without an error. Notice that the model has no
knowledge about linguistic structure whatsoever. It learns to associate two numerical vectors
(holding word indices) with a one-hot vector representing the answer word. Here is the system
log evaluation:

Thing get worse when we add contexts meaning push the model must remember the longer story:
The log evaluation:
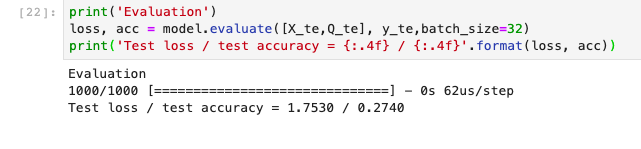
as you can see the test accuracy is just 0.274 if we make the context before and after is 10
we will try to improve this in the next post with LSTM
the working experiment can be found at http://14.232.166.121:8880 andy>memory_QA>rnn_qa.ipynb


