Long Short Term Memory Networks (LSTM)
RNN vs LSTM
let’s say we have a regular neural network which recognizes images and we fitted this image. And the neural neural network guesses that the image is most likely a dog with a small chance of being a wolf and an even smaller chance of being a goldfish. But, what if this image is actually a wolf? How would the neural network know? So, let’s say we’re watching a TV show about nature and the previous image before the wolf was a bear and the previous one was a fox.
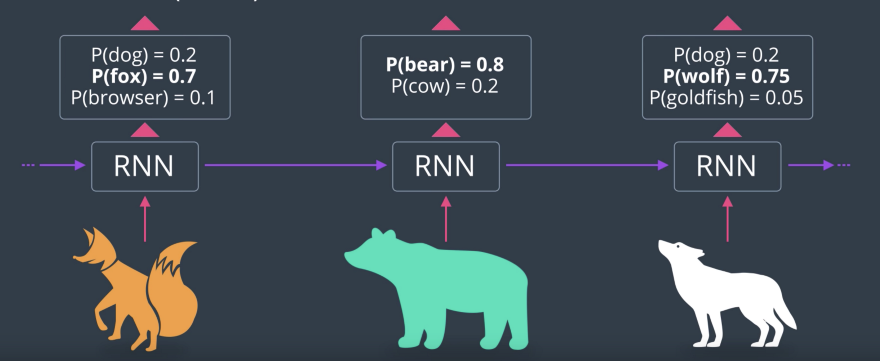
So, in this case, we want to use this information to hint to us that the last image is a wolf and not a dog. So, what we do is analyze each image with the same copy of a neural network. But, we use the output of the neural network as a part of the input of the next one. And, that will actually improve our results. Mathematically, this is simple. We just combine the vectors in a linear function, which will then be squished with an activation function, which could be sigmoid or hyperbolic tanh. This way, we can use previous information and the final neural network will know that the show is about wild animals in the forest and actually use this information to correctly predict that the image is of a wolf and not a dog. And, this is basically how recurrent neural networks work.
However, this has some drawbacks. Let’s say the bear appeared a while ago and the two recent images are a tree and a squirrel. Based on those two, we don’t really know if the new image is a dog or a wolf.
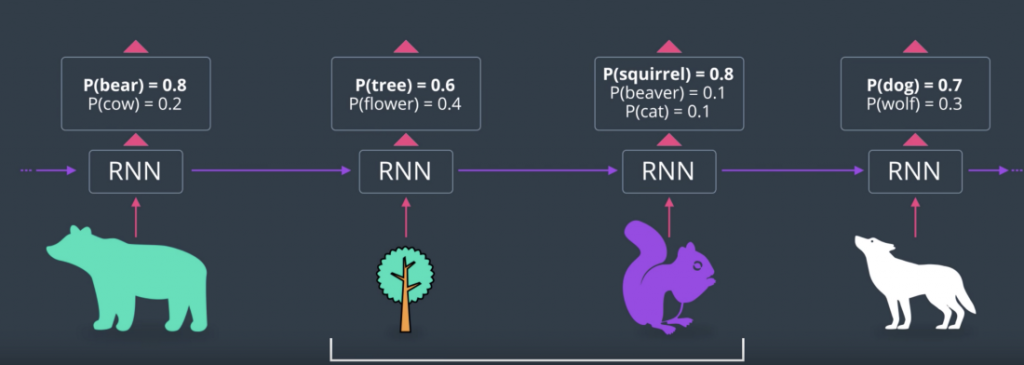
Since trees and squirrels are just as associated to domestic animals as they are with forest animals. So, the information about being in the forest comes all the way back from the bear. But, as we’ve already experienced, information coming in gets repeatedly squished by sigmoid functions and even worse than that, training a network using back propagation all the way back, will lead to problems such as the vanishing gradient problem etc. So, by this point pretty much all the bear information has been lost. That’s a problem with recurring neural networks.
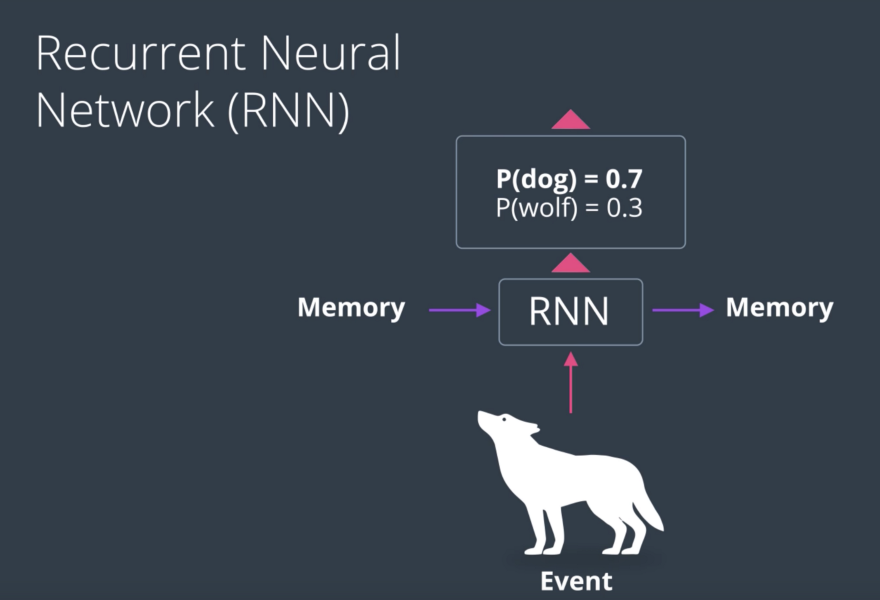
RNNs, have a hard time storing long term memory and this is where LSTMs or long short term memory networks will come to the rescue. So, as a small summary, an RNN works as follows:
memory comes in and merges with a current event and the output comes out as a prediction of what the input is. And also, as part of the input for the next iteration of the neural network.
And in a similar way, an LSTM works as follows:
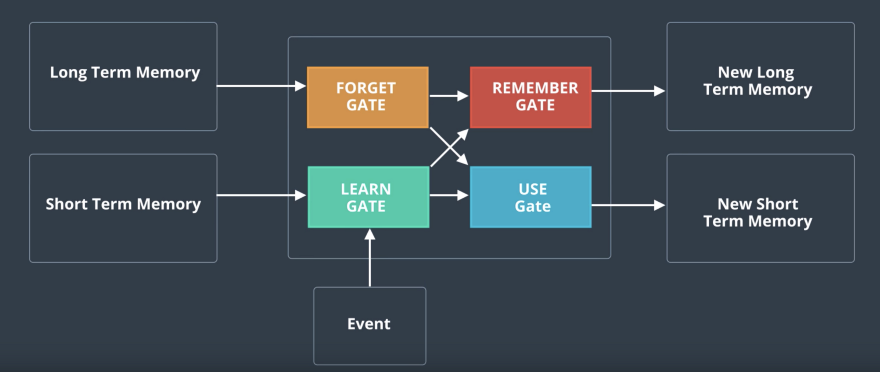
it keeps track not just of memory but of long term memory, which comes in and comes out. And also, short term memory, which also comes in and comes out. And in every stage, the long and short term memory in the event get merged. And from there, we get a new long term memory, short term memory and a prediction.
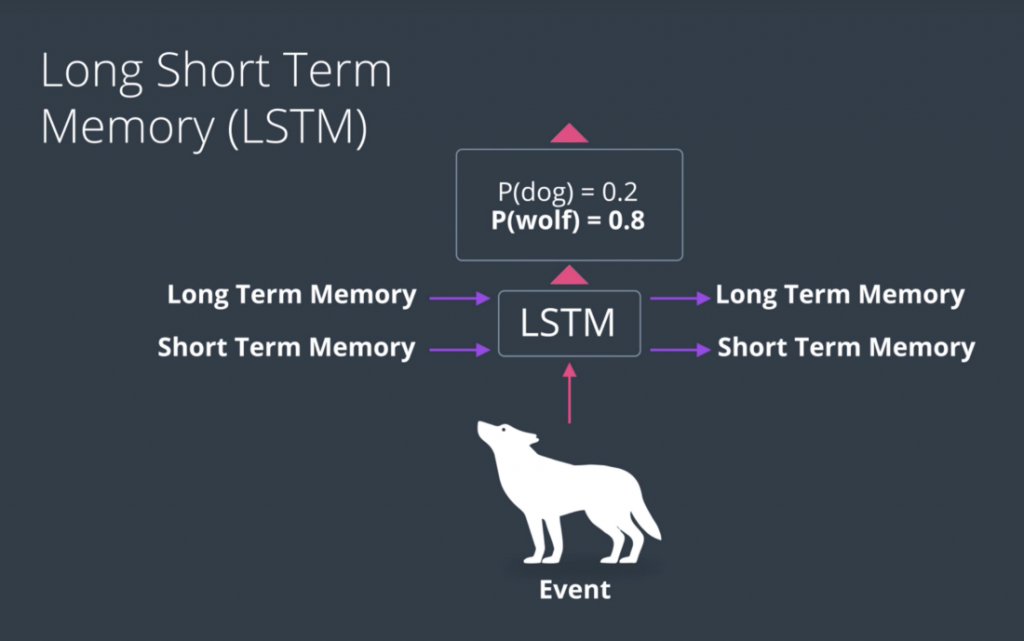
Basics of LSTM
We have the following problem: we are watching a TV show and we have a long term memory which is that the show is about nature and science and lots of forest animal have appeared. We also have a short term memory which is what we have recently seen which is squirrels and trees. And we have a current event which is what we just saw, the image of a dog which could also be a wolf. And we want these three things to combine to form a prediction of what our image is. In this case, the long term memory which says that the show is about forest animals will give us a hint that the picture is of a wolf and not a dog. We also want the three pieces of information, long term memory, short term memory, and the event, to help us update the long term memory.
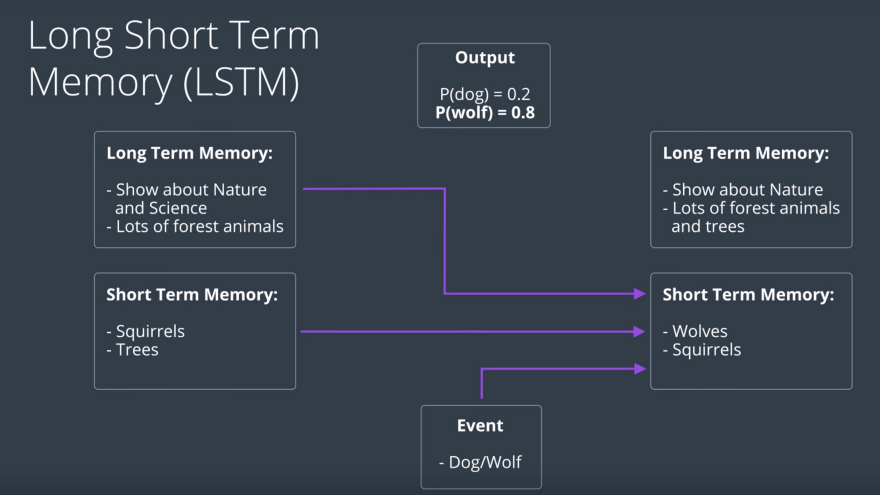
LSTM works as follows:
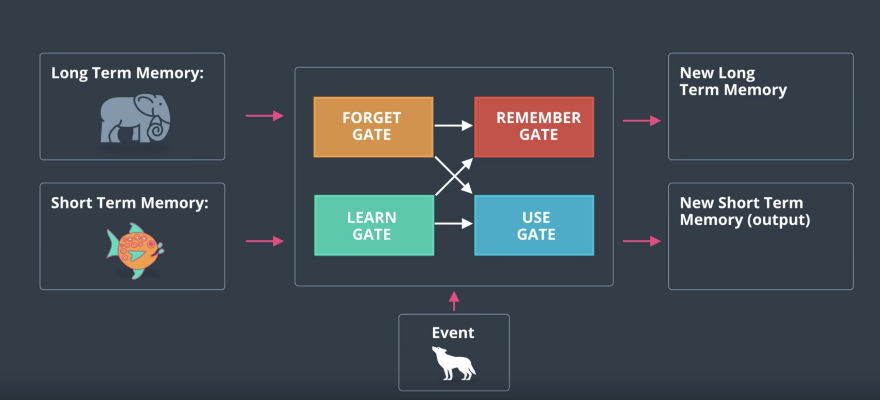
The three pieces of information go inside the node and then some math happens and then the new pieces of information get updated and come out. There is a long term memory, a short term memory and the prediction of the event.
Architecture of LSTM
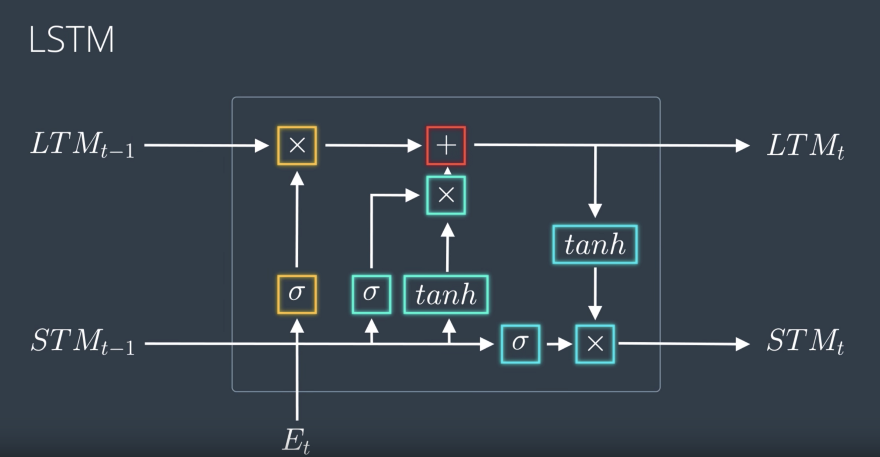
The LSTM architecture is very similar to RNN, except with a lot more nodes inside and with two inputs and outputs since it keeps track of the long- and short-term memories. And as I said, the short-term memory is, again, the output or prediction. Don’t get scared. These are actually not as complicated as they look.
The Learn Gate

What the learn gate does is the following:
It takes a short term memory and the event and it joins it. Actually, it does a bit more. It takes the short term memory and the event and it combines hem and then it ignores a bit of it keeping the important part of it.
And how does this work mathematically?
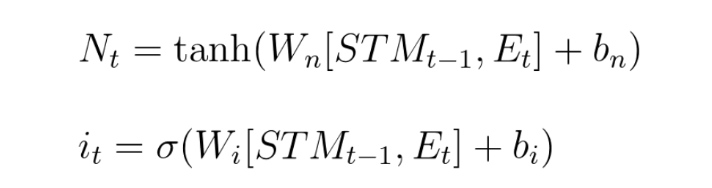
The Forget Gate
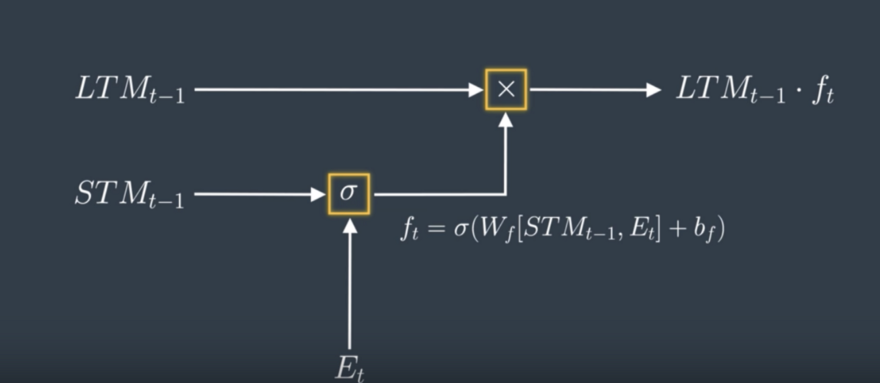
How does the Forget Gate work mathematically?
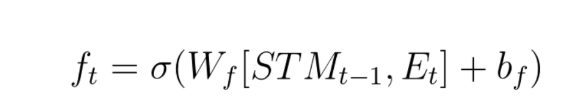
The Remember Gate
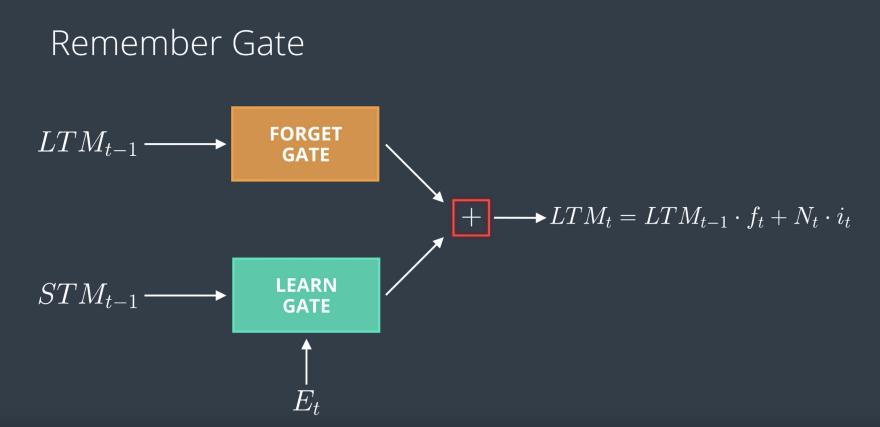
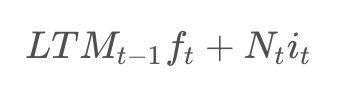
The Use Gate
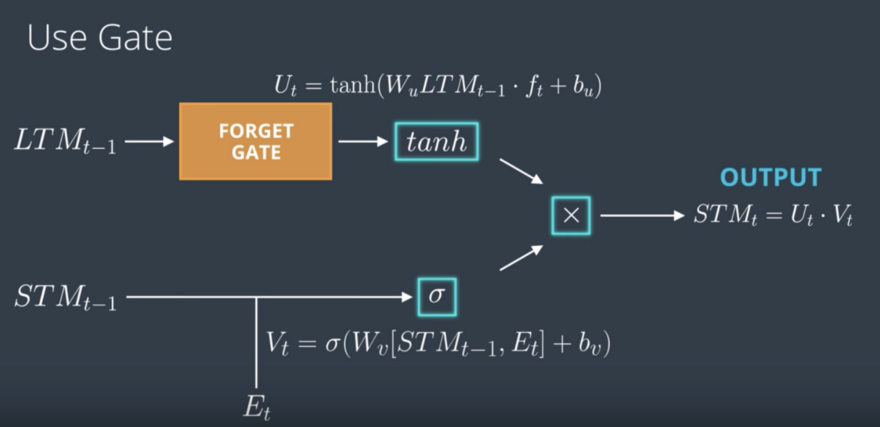
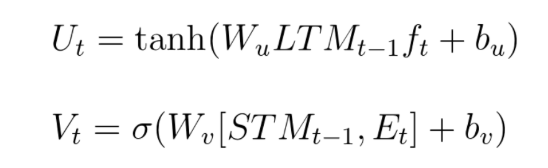
Put it all together: