Survey on Neural Summarization Methods
Introduction
automatic text summarization is the process of shortening a text while keeping the main content and ideas of the documents. With the large amount of text published online such as product’s reviews and the quick capture of these document’s content is critical for decision making. Therefore; manual text summarization is not feasible anymore.
The dominant approach for text summarization up to the blooming of Deep Learning is shallow unsupervised learning information retrieval information models. Neural summarization start in 2014 with the research work of [K˚ageb¨ack et al., 2014] showing that the neural continuous vector space models are promising for text summarization; the research also proved the superior performance in comparison to the classical shallow machine learning methods
The aim of this literature review is to survey the recent work on neural automatic text summarization models. This survey start with the fundamentals on document summarization following by details of recent significant neural text summarization models. The survey also discuss the promising directions for the future research and general conclusion
Background
Summarization Factors
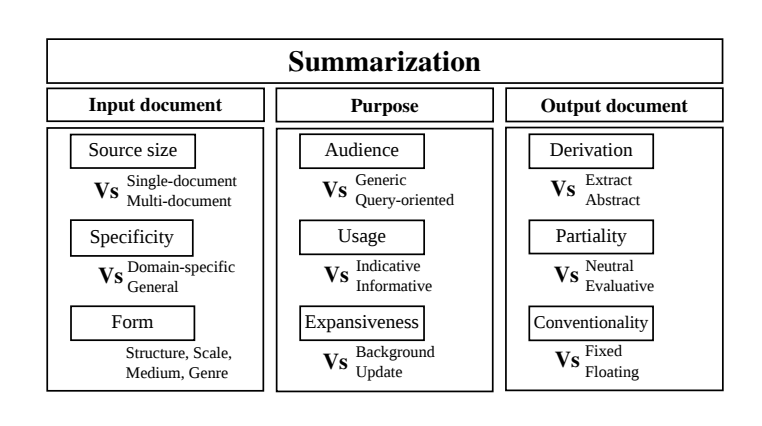
there are three main factors in text summarization: input, output and purpose; we will briefly discuss three factors
input factors
single-document or multi-document: this factor concerns about the number of input documents that the summarization system take [Jones et al., 1999]
Monolingual, multilingual or cross-lingual: this factor related to to the number of languages that system can handle. Monolingual system has the input and output in the same language; the multilingual systems handle the input-output pairs in the same language across different languages. in contrast; cross-lingual system handle input-output pairs which are not in the same language
purpose factors
informative or indicative: the indicative summary conveys the relevant contents of the original documents so the reader can select document that align with their interests to read further. mean while; the informative is to replace the original documents with the important contents is concerned
output factors
extractive or abstractive: extractive summarizer selects text snippets (words, phrases, sentences) from the source documents; while abstractive generate the important text snippets to convey the main ideas of the source of documents
Evaluation of Summarization Systems
The most popular and cheap method for evaluating of text summarizer is Recall-Oriented Understudy for Gisting Evaluation (ROUGE) [Lin, 2004] along with human ratings. There type of ROUGE that are commonly used are ROUGE-N, ROUGE-L and ROUGE-SU.
ROUGE-N computes the percentage of n-gram overlapping of system and reference summaries
ROUGE-L computes the sum of the longest in sequence matches of each reference sentence to the system summary
ROUGE-SU measures the percentage of skip-bigrams and unigrams overlapping
Summarization Techniques
Most early works on single-document extractive summarization employ statistical techniques. Such algorithms rank each sentence based on its relation to the other sentences by using pre defined formulas Later works on text summarization address the problem by creating sentence representations of the documents and utilizing machine learning algorithms. These models manually select the appropriate features, and train supervised models to classify whether to include the sentence in the summary [wong 2008] . The core of abstractive summarization techniques is to identify the main ideas in the documents and encode them into feature representations. These encoded features are then passed to natural language generation (NLG) systems Most of the early work on abstractive summarization uses semi-manual process of identifying the main ideas of the document(s). Prior knowledge such as scripts and templates are usually used to produce summaries
Neural-Based Summarization Techniques
With the blooming of deep learning, neural summarizers has become an attracted considerable attention for automatic summarization. The neural models often achieve better performance in comparison to the traditional model if we got a huge amount of data
Most neural-based summarizers use the following pipeline: 1) words are transformed to continuous vectors, called word embeddings, by a look-up table; 2) sentences/documents are encoded as continuous vectors using the word embeddings; 3) sentence/document representations (sometimes also word embeddings) are then fed to a model for selection (extractive summarization) or generation (abstractive summarization).
Neural networks can be used in any of the above three steps. In step 1, we can use neural networks to obtain pre-learned look-up tables (such as Word2Vec, CW vectors, and GloVe). In step 2, neural networks, such as convolutional neural networks (CNNs) or recurrent neural networks(RNNs), can be used as encoders for extracting sentence/document features. In step 3, neural network models can be used as regressors for ranking/selection (extraction) or decoders for generation (abstraction).
Extractive Models
Extractive summarizers, which are selection-based methods, need to solve the following two critical challenges: 1) how to represent sentences; 2) how to select the most appropriate sentences, taking into account of the coverage and the redundancy.
[K˚ageb¨ack et al., 2014] proposes to represent sentences as continuous vectors that are obtained by either adding the word embeddings or using an unfolding Recursive Auto-encoder (RAE) on word embedding. The RAE is trained in an unsupervised manner by back propagation method with self-reconstruction error. The pre-computed word embeddings from Collobert and Weston’s model (CW vectors) or Mikolov et al.’s model (W2V vectors) are directly used without fine-tuning. The selection task is choosing summary S as an optimization problem that maximizes the linear combination of the diversity of the sentences R and the coverage of the input text L.
[Cao et al., 2015] propose PriorSum which uses the CNN learned features concatenated with document independent features as the sentence representation. Three document-independent features are used: 1) sentence position; 2) averaged term frequency of words in the sentence based on the document; 3) averaged term frequency of words in the sentence based on the cluster (multi-document summarization). The CNN used in PriorSum has multiple-layers with alternating convolution and pooling operations. The filters in the convolution layers have different window sizes and two-stage max-over-time-pooling operations are performed in the pooling layers. The parameters in this CNN is updated by applying the diagonal variant of AdaGrad with mini-batches PriorSum is a supervised model that requires the gold standard summaries during training. PriorSum follows the traditional supervised extractive framework: it first ranks each sentence and then selects the top k ranked non-redundant sentences as the final summary During training, each sentence in the document is associated with the ROUGE-2 score (stopwords removed) with respect to the gold standard summary. Then a linear regression model is trained to estimate these ROUGE-2 scores by updating the regression weights
[Nallapati et al., 2017] propose SummaRuNNer employs a two-layer bi-directional RNN for sentences and document representations. The first layer of the RNN is a bi-directional GRU that runs on words level: it takes word embeddings in a sentence as the inputs and produces a set of hidden states. These hidden states are averaged into a vector, which is used as the sentence representation. The second layer of the RNN is also a bi-directional GRU, and it runs on the sentence-level by taking the sentence representations obtained by the first layer as inputs. The hidden states of the second layer are then combined into a vector d (document representation) through a non-linear transformation. The authors frame the task of sentence selection as a sequentially sentence labeling problem which uses the hidden states (h1, , hm) from the second layer of the encoder RNN directly for the binary decision (modeled by a sigmoid function)
Abstractive Models
Abstractive summarizers focus on capturing the meaning representation of the whole document and then generate an abstractive summary based on this meaning representation. Therefore, neural-based abstractive summarizers, which are generation-based methods, need to make the following two decisions: 1) how to represent the whole document by an encoder; 2) how to generate the words sequence by a decoder
[Rush et al., 2015] proposes three encoder structures to capture the meaning representation of a document. Bag-of-Words Encoder: The first encoder basically computes the summation of the word embeddings appeared in the sequence. Convolutional Encoder : This encoder utilizes a CNN model with multiple alternating convolution and 2-element-max-pooling layers. Attention-Based Encoder : This encoder produces a document representation at each time step based on the previous C words (context) generated by the decoder. The decoder uses a feed-forward neural network-based language model (NNLM) for estimating the probability distribution that generates the word at each time step t
[Nallapati et al., 2016] proposes a feature-rich hierarchical attentive encoder based on the bidirectional-GRU to represent the document. The encoder takes the input vector obtained by concatenating the word embedding with additional linguistic features. The additional linguistic features used in their model are parts-of-speech (POS) tags, named-entity (NER) tags, term-frequency (TF) and inverse document frequency (IDF) of the word. The continuous features (TF and IDF) are first discretized into a fixed number of bins and then encoded into one-hot vectors as other discrete features. All the one-hot vectors are then transformed into continuous vectors by embedding matrices and these continuous vectors are concatenated into a single long vector, which is then fed into the encoder. Hierarchical attention: The hierarchical encoder has two RNNs; one runs on the word-level and one runs on the sentence-level. The hierarchical attention proposed by the authors basically re-weigh the word attentions by the corresponding sentence-level attention. The document representation dt is then obtained by the weighted sum of the feature-rich input vectors. The decoder is based on uni-directional GRU.
[See et al., 2017] proposed a neural network architecture called Pointer-Generator Networks. The encoder of the Pointer-Generator network is simply a single-layer bidirectional LSTM. It computes the document representation dt based on the attention weights and the encoder’s hidden states. The The basic building block of decoder is a single-layer uni-directional LSTM. Moreover, the authors propose a coverage mechanism for penalizing repeated attentions on already attended words.
Discussions and the Promising Paths for Future Research
In summarization, one critical issue is to represent the semantic meanings of the sentences and documents. Neural-based models display superior performance on automatically extracting these feature representations. However, deep neural network models are neither transparent enough nor integrating with the prior knowledge well. More analysis and understanding of the neural-based models are needed for further exploiting these models. In addition, the current neural-based models have the following limitations: 1) they are unable to deal with sequences longer than a few thousand words due to the large memory requirement of these models; 2) they are unable to work well on small-scale datasets due to the large amount of parameters these models have; 3) they are very slow to train due to the complexity of the models. There are many very interesting and promising directions for future research on text summarization. We proposed three directions in this review: 1)using the pre-trained technique such as ELMo, UMFiT or BERT to get the better result on text summarization to tackle the limitation of data
2) using the reinforcement learning approaches, such as the actor-critic algorithm, to train the neural-based models; 3) exploiting techniques in text simplification to transform documents into simpler ones for summarizers to process.
Conclusion
This survey presented the potential of neural-based techniques in automatic text summarization, based on the examination of the-state-of-the-art extractive and abstractive summarizers.
Neural-based models are promising for text summarization in terms of the performance when
large-scale datasets are available for training. However, many challenges with neural-based
models still remain unsolved. Future research directions such as adding the reinforcement
learning algorithms and text simplification methods to the current neural-based models are
provided to the researchers
References
[K˚ageb¨ack et al., 2014] K˚ageb¨ack, M., Mogren, O., Tahmasebi, N., and Dubhashi, D. (2014). Extractive summarization using continuous vector space models. In Proceedings of the 2nd Workshop on Continuous Vector Space Models and their Compositionality (CVSC)@ EACL, pages 31–39.
[Jones et al., 1999] Jones, K. S. et al. (1999). Automatic summarizing: factors and directions. Advances in automatic text summarization, pages 1–12.
[Wong et al., 2008] Wong, K.-F., Wu, M., and Li, W. (2008). Extractive summarization using supervised and semi-supervised learning. In Proceedings of the 22nd International Conference on Computational LinguisticsVolume 1, pages 985–992. Association for Computational Linguistics
[Cao et al., 2015] Cao, Z., Wei, F., Li, S., Li, W., Zhou, M., and Wang, H. (2015). Learning summary prior representation for extractive summarization. In ACL.
[Nallapati et al., 2017] Nallapati, R., Zhai, F., and Zhou, B. (2017). SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA., pages 3075–3081.
[Rush et al., 2015] Rush, A. M., Chopra, S., and Weston, J. (2015). A neural attention model for abstractive sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17-21, 2015, pages 379–389.
[Nallapati et al., 2016] Nallapati, R., Zhou, B., dos Santos, C. N., G¨ul¸cehre, C¸ ., and Xiang, B. (2016). Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, August 11-12, 2016, pages 280–290.
[See et al., 2017] See, A., Liu, P. J., and Manning, C. D. (2017). Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 – August 4, Volume 1: Long Papers, pages 1073–1083.


