Survey on Non-Task Oriented Dialogue systems

Introduction
Last few decades have witnessed substantial breakthroughs on several areas of speech and language understanding research, specifically for building human to machine conversational dialog systems. Dialog systems, also known as interactive conversational agents, virtual agents or sometimes chatbots, are useful in a wide range of applications ranging from technical support services to language learning tools and entertainment. Recent success in deep neural networks has spurred the research in building data-driven dialog models. In this article, we give an overview to these recent advances on non task oriented dialogue systems from various perspectives and discuss some possible research directions
Non Task Oriented Dialogue Systems
Unlike task-oriented dialogue systems, which aim to complete specific tasks for user, non-task-oriented dialogue systems (also known as chatbots) focus on conversing with human on open domains [Ritter 2011]. In general, chat bots are implemented either by generative methods or retrieval-based methods. Generative models are able to generate more proper responses that could have never appeared in the corpus, while retrieval-based models enjoy the advantage of informative and fluent responses [lu 2011], because they select a proper response for the current conversation from a repository with response selection algorithms. In the following sections, we will focus into the neural generative models, one of the most popular research topics in recent years, and discuss their drawbacks and possible improvements.
Neural Generative Models
Nowadays, a large amount of conversational exchanges is available in social media websites such as Twitter and Reddit, which raise the prospect of building data-driven models [Ritter 2011]. proposed a generative probabilistic model, which is based on phrase-based Statistical Machine Translation, to model conversations on micro-blogging. It viewed the response generation problem as a translation problem, where a post needs to be translated into a response. However,
generating responses was found to be considerably more difficult than translating between languages. It is likely due to the wide range of plausible responses and the lack of phrase alignment between the post and the response. The success of applying deep learning in machine translation, namely Neural Machine Translation, spurs the enthusiasm of researches in neural generative dialogue systems. In the following sections, we first introduce the sequence-to-sequence models, the foundation of neural generative models. Then, we discuss hot research topics in the direction including incorporating dialogue context, improving the response diversity, modeling topics and personalities, leveraging outside knowledge base, the interactive learning and evaluation.
Sequence-to-Sequence Models
Given a source sequence (message) X consisting of T words and a target sequence (response) Y f length T ,the model maximizes the generation probability of Y conditioned on X; Specifically, a sequence-to-sequence model (or Seq2Seq) is in an encoder-decoder structure. The encoder reads X word by word and represents it as a context vector c through a recurrent neural network (RNN),and then the decoder estimates the generation probability of Y with c as the input. The encoder RNN calculates the context vector c by
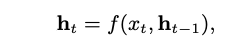
where ht is the hidden state at time step t, f is a non-linear function such as long-short term memory unit (LSTM) and gated recurrent unit (GRU)], and c is the hidden state corresponding to the last word hT . The decoder is a standard RNN language model with an additional conditional context vector c. The probability distribution pt of candidate words at every time t is calculated as
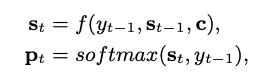
where st is the hidden state of the decoder RNN at time t and yt1 is the word at time t1 in the response sequence. [Bahdanau 2014] [Luong 2015] improved the performance by the attention mechanism, where each word in Y is conditioned on different context vector c, with the observation that each word in Y may relate to different parts in x. In general, these models utilize neural networks to represent dialogue histories and to generate appropriate responses. Such models are able to leverage a large amount of data in order to learn meaningful natural language representations and generation strategies, while requiring a minimum amount of domain knowledge and handcrafting
Dialogue Context
The ability to take into account previous utterances is key to building dialog systems that can keep conversations active and engaging. [Serban 2016] used hierarchical models, first capturing the meaning of individual utterances and then integrating them as discourses. [Xing 2017] extended the hierarchical structure with the attention mechanism to attend to important parts within and among utterances with word level attention and utterance level attention, respectively
Challenges and Remedies
Response Diversity
A challenging problem in current sequence-to-sequence dialogue systems is that they tend to generate trivial or noncommittal, universally relevant responses with little meaning, which are often involving high frequency phrases along the lines of I dont know or Im OK. This behavior can be ascribed to the relative high frequency of generic responses like I dont know in conversational datasets, in contrast with the relative sparsity of more informative alternative responses. One promising approach to alleviate such challenge is to find a better objective function. [Li 2016] pointed out that neural models assign high probability to “safe responses when optimizing the likelihood of outputs given inputs. They used a Maximum Mutual Information (MMI), which was first introduced in speech recognition , as an optimization objective It measured the mutual dependence between inputs and outputs, where it took into consideration the inverse dependency of responses on messages. [Serban 2017] presented a latent Variable Hierarchical Recurrent Encoder-Decoder (VHRED) model that also aims to generate less bland and more specific responses. It extends the HRED model by adding a high-dimensional stochastic latent variable to the target. This additional latent variable is meant to address the challenge associated with the shallow generation process. , this process is problematic from an inference standpoint because the generation model is forced to produce a high-level structure-i.e., an entire response-on a word-by-word basis. This generation process is made easier in the VHRED model, as the model exploits a high-dimensional latent variable that determines high-level aspects of the response (topic, names, verb, etc.), so that the other parts of the model can focus on lower level aspects of generation, e.g., ensuring fluency. The VHRED model incidentally helps reducing blandness. Indeed, as the content of the response is conditioned on the latent variable, the generated response is only bland and devoid of semantic content if the latent variable determines that the response should be as such. More recently, [Zhang 2018] presented a model that also introduces an additional variable (modeled using a Gaussian kernel layer), which is added to control the level of specificity of the response, going from bland to very specific.
Speaker Consistency
It has been shown that the popular seq2seq approach often produces conversations that are incoherent [Li 2016] where the system may for instance contradict what it had just said in the previous turn (or sometimes even in the same turn). While some of this effect can be attributed to the limitation of the learning algorithms. [Li 2016] suggested that the main cause of this inconsistency is probably due to the training data itself. This sets apart the response generation task from more traditional NLP tasks: While models for other tasks such as machine translation are trained on data that is mostly one-to-one semantically, conversational data is often one-to-many or many-to-many as the above example implies. As one-to-many training instances are akin to noise to any learning algorithm, one needs more expressive models that exploits a richer input to better account for such diverse responses.[Li 2016] did so with a persona-based response generation system, which is an extension of the LSTM mode hat uses speaker embeddings in addition to word embeddings. Intuitively, these two types of embeddings work similarly: while word embeddings form a latent space in which spacial proximity (i.e., low Euclidean distance) means two words are semantically or functionally close, speaker embeddings also constitute a latent space in which two nearby speakers tend to converse in the same way, e.g., having similar speaking styles (e.g., British English) or often talking about the same topic (e.g., sports). More recently, [Luan 2017] presented an extension of the speaker embedding model of [Li 2016] which combines a seq2seq model trained on conversational datasets with an autoencoder trained on non-conversational data, where the seq2seq and autoencoder are combined in a multitask learning setup. The tying of the decoder parameters of both seq2seq and autoencoder enables [Luan 2017] to train a response generation system for a given persona without actually requiring any conversational data available for that persona. This is an advantage of their approach, as conversational data for a given user or persona might not always be available
Word Repetitions
Word or content repetition is a common problem with neural generation tasks other than machine translation, as has been noted with tasks such as response generation, image captioning, visual story generation, and general language modeling. While machine translation is a relatively one-to-one task where each piece of information in the source (e.g., a name) is usually conveyed exactly once in the target, other tasks such as dialogue or story generation are much less constrained, and a given word or phrase in the source can map to zero or multiple words or phrases in the target. This effectively makes the response generation task much more challenging, as generating a given word or phrase doesn’t completely preclude the need of generating the same word or phrase again. In light of the above limitations. [Shao 2017] proposed a new model that adds self-attention to the decoder, aiming at improving the generation of longer and coherent responses while incidentally mitigating the word repetition problem. Target-side attention helps the model more easily keep track of what information has been generated in the output so far so that the model can more easily discriminate against unwanted word or phrase repetitions.
Conclusion
Deep learning has become a basic technique in dialogue systems. Researchers investigated on applying neural networks to the different components of a traditional task-oriented dialogue system, including natural language understanding, natural language generation, dialogue state tracking. Recent years, end-to-end frameworks become popular in not only the non-task-oriented chit-chat dialogue systems, but also the task-oriented ones. Deep learning is capable of leveraging large amount of data and is promising to build up a unified intelligent dialogue system. It is blurring the boundaries between the task-oriented dialogue systems and non task-oriented systems. In particular, the chit-chat dialogues are modeled by the sequence-to-sequence model directly. The task completion models are also moving towards an end-to-end trainable style with reinforcement learning representing the state-action space and combing the whole pipelines. It is worth noting that current end-to-end models are still far from perfect. Despite the aforementioned achievements, the problems remain challenging. Next, we discuss some possible research directions:
Swift Warm-Up: Although end-to-end models have drawn most of the recent research attention, we still need to rely on traditional pipelines in practical dialogue engineering, especially in a new domain warmup stage. The daily conversation data is quite “big”, however, the dialogue data for a specific domain is quite limited. In particular, domain specific dialogue data collection and dialogue system construction are labor some. Neural network based models are better at leveraging large amount of data. We need new way to bridge over the warm-up stage. It is promising that the dialogue agent has the ability to learn by itself from the interactions with human.
Deep Understanding. Current neural network based dialogue systems heavily rely on the huge amount of different types of annotated data, and structured knowledge base and conversation data. They learn to speak by imitating a response again and again, just like an infant, and the responses are still lack of diversity and sometimes are not meaningful. Hence, the dialogue agent should be able to learn more effectively with a deep understanding of the language and the real world. Specifically, it remains much potential if a dialogue agent can learn from human instruction to get rid of repeatedly training. Since a great quantity of knowledge is available on the Internet, a dialogue agent can be smarter if it is capable of utilizing such unstructured knowledge resource to make comprehension. Last but not least, a dialogue agent should be able to make reasonable inference, find something new, share its knowledge across domains, instead of repeating the words like a parrot
Reference
A. Ritter, C. Cherry, and W. B. Dolan. Data-driven response generation in social media. In Conference on Empirical Methods in Natural Language Processing, pages 583–593, 2011.
Z. Ji, Z. Lu, and H. Li. An information retrieval approach to short text conversation. arXiv preprint arXiv:1408.6988, 2014.
D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014
T. Luong, I. Sutskever, Q. Le, O. Vinyals, andW. Zaremba. Addressing the rare word problem in neural machine translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 11–19, Beijing, China, July 2015. Association for Computational Linguistics.
I. Serban, A. Sordoni, Y. Bengio, A. Courville, and J. Pineau. Building end-to-end dialogue systems using generative hierarchical neural network models, 2016.
Xing, W. Wu, Y. Wu, M. Zhou, Y. Huang, and W. Y. Ma. Hierarchical recurrent attention network for response generation. 2017.
Serban, I. V., Sordoni, A., Lowe, R., Charlin, L., Pineau, J., Courville, A., and Bengio, Y. (2017). A
hierarchical latent variable encoder-decoder model for generating dialogues. In AAAI.
Li, J., Galley, M., Brockett, C., Gao, J., and Dolan, B. (2016b). A persona-based neural conversation
model. In ACL.
Xing, W. Wu, Y. Wu, M. Zhou, Y. Huang, and W. Y. Ma. Hierarchical recurrent attention network for response generation. 2017.
Serban, I. V., Sordoni, A., Lowe, R., Charlin, L., Pineau, J., Courville, A., and Bengio, Y. (2017). A
hierarchical latent variable encoder-decoder model for generating dialogues. In AAAI.
Luan, Y., Brockett, C., Dolan, B., Gao, J., and Galley, M. (2017). Multi-task learning for speaker role adaptation in neural conversation models. In IJCNLP.
Shao, Y., Gouws, S., Britz, D., Goldie, A., Strope, B., and Kurzweil, R. (2017). Generating highquality and informative conversation responses with sequence-to-sequence models. In EMNLP.


