Recurrent Embedding Dialogue Policy

In this blog post we will investigate together the neural network architecture that empower the rasa core ‘s dialogue policy manager. Let dive into their original paper
Abstract

one of the limitation of Machine-learning based dialogue manager is to use knowledge from one task’s domain and apply to other domains (this sounds like transfer learning). This paper propose a neural network architecture using memory and attention mechanism to break this limitation called recurrent embedding dialogue policy
Introduction

hand-crafted dialogue dialogue system has been quite popular with the limitation of extending its capability to new domains (hand-crafted == rules based ^^!) and utilizing the annotated training data. This paper will follow the end-to-end system (data-driven) approach

you may heard about multi-task so what is the difference between multi-task and cross-task. The answer is all about how the network is trained. cross-task means transfer-learning when network learn knowledge from one task and apply to another tasks. In this paper, cross-task means learning to deal with uncooperative users from cooperative users. multi-task means network learn to complete many tasks at the same time
When you train rasa core using embedding policy; you prepare many stories including happy stories and unhappy stories and rasa core is trained story by story. This is exactly cross-task mean
Related Work

This section provide some related works relating to modular system and end-to-end system. modular system usually refers to a system designed with many sub-system or modules to cover a task while end-to-end is one module to rule them all

Domain adaptation means transfer learning … that’s it
research paper always try to make other people feel scary by using a lot of terminology with the same meaning … bloody hell @.@

What is the difference between classification and ranking.
classification mean you assign a 1-to-1 relation to the output of the model; for example this is a dog not a cat
ranking mean you assign a 1-to-n relation to the output of the model; take one example this is 60% chance of dog, 20% of cat, 10% fish and 10% of rabbit
the proposal method of this paper is ranking

once again, this emphasize the task of the proposed network; transfer learning the slot filling task (manage the dialog) from one domain to another domain
Recurrent Embedding Dialogue Policy
This is the heart of the paper; we will read and understand the clever idea of this paper; this picture illustrates the high level of the whole system
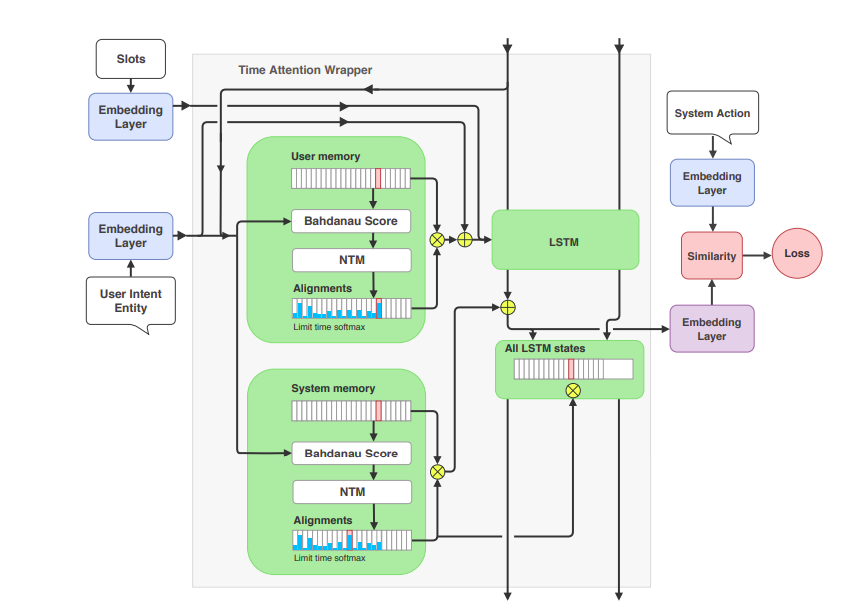


Featurization
this is the first step in our system called featurization. The word vectorization may seem to be easy to understand than this terminology. ok! the first step is to vectorize the user input; system action and slots; why we need to do this because they are all texts . you have bunch of method for text vectorization: bag-of-word, tf-idf .. etc in this paper they choose bag of word 😀
Embedding layers
the next step is to embed the vectors of user input, system action and slot into another vector space; how to do this? simple ! you connect the vector with one or two hidden fully connected layers and you get the embeddings; in the same manner of word2vec
Attention
if you need a refresh about attention mechanism and how attention is used as a way to read from and write to memory take a look at these two posts
so what is attention exactly?: attention is just a way for calculating the similarity of two matrix by matrix multiplication
using the knowledge of similarity they can perform some other task such as decoding sentence or encoding the similarity into another matrix and retrieve back from it
this is paper they use attention to calculate the similarity between the previous user input and current user input and encode this information into a matrix (memory bank); the similar manner is applied for previous system action and current system action. so we got two big memory as depicted in the picture
RNN
because user input and system action has the relation; there should be another step to abstract the connection between the memory of user input and the memory of system action; how they do it. they propose a very clever way by feeding the memory vector of user input action to the LSTM to get out the hidden states; then these hidden states are multiplied with the memory vector of system action. This is clever because we got the similarity in the time dimension between the user-input and system action. in other words, the system can learn at a particular time step what is the proper system action
Similarity
the multiplied vector of user-input and all the previous system actions is then compared to the vector of current system action in the training phase. and of course we want to maximize the similarity between them
and that all you need to remember from this paper
if you want to digest every details of the paper, please take a look at https://arxiv.org/pdf/1811.11707.pdf


