Natural Language Processing
Topic Modeling
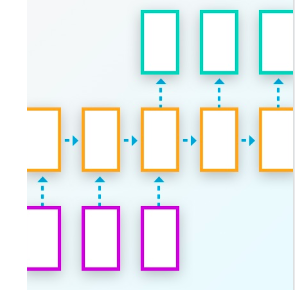
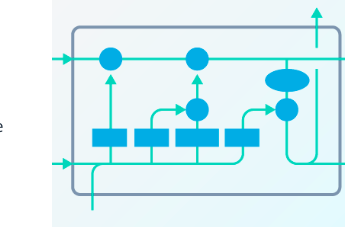
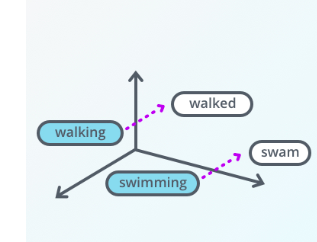
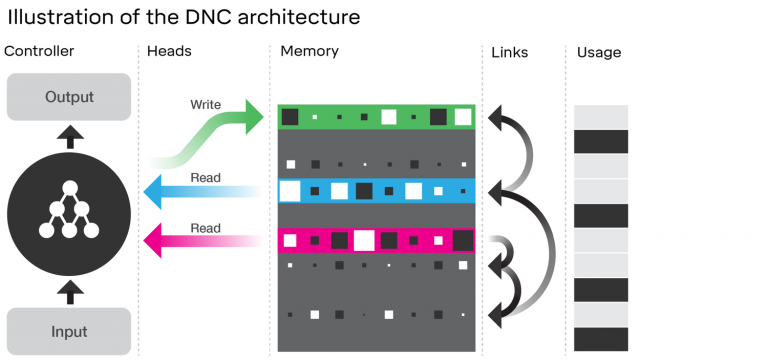
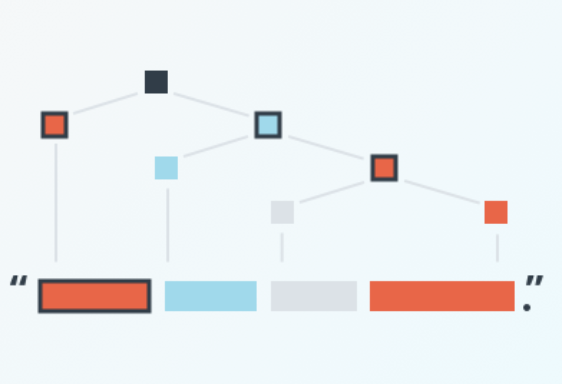
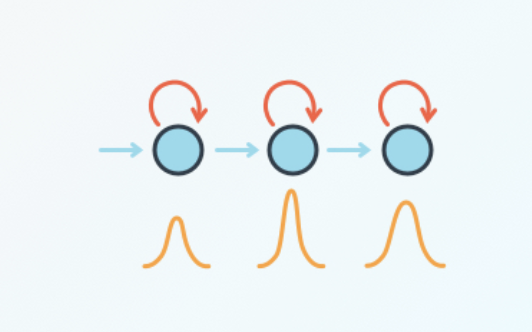
Intro The bag-of-words approach tries to represent documents in a dataset directly using the words that appear in them. But often, these words are predicated on some underlying parameters are very among documents such as a topic being discussed. In …